
Lambda架构概述
什么是 Lambda 架构?
Lambda 架构是一种用于设计和实现大规模数据计算系统的架构模式,其核心目标是平衡延迟、吞吐量和容错性,以应对海量数据的实时查询和分析需求。
它诞生的背景是传统批处理系统(如 Hadoop、Hive)无法满足低延迟查询场景,而纯流处理系统又难以保证数据准确性和历史数据的计算。Lambda 架构通过巧妙地结合两种处理范式来解决这一矛盾。
核心思想:三层并行处理
Lambda 架构将系统分为三层,对同一份数据进行并行的、不同方式的处理,最终将结果合并提供统一的查询视图。
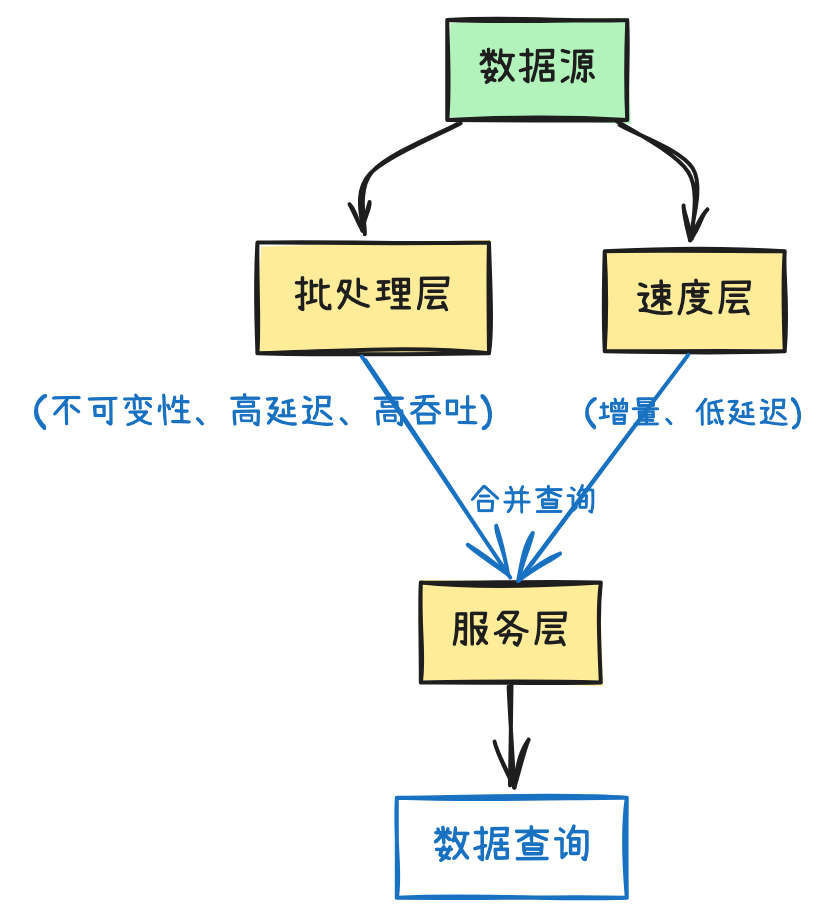
详细分解三层架构
1. 批处理层
职责:管理主数据集(Master Dataset),并预先计算批处理视图。
特点:
不可变性:主数据集是一个仅追加、一般不修改的原始数据序列(如 HDFS 文件、S3 对象)。
高延迟、高吞吐:处理所有历史数据,计算非常精确,但延迟通常从几分钟到几小时不等。
容错性:基于分布式存储和计算,天然容错。
技术选型:
存储:HDFS, Amazon S3, HBase
计算:Apache Hadoop MapReduce, Apache Spark
输出:批处理视图,例如一个按天聚合的用户行为汇总表。
2. 速度层
职责:处理自上次批处理完成后到达的新数据(增量数据),并生成实时视图以弥补批处理的高延迟。
特点:
低延迟:处理实时数据流,延迟在秒或毫秒级。
增量计算:只关心新到的数据。
复杂性:由于要处理乱序、迟到数据等,逻辑比批处理层更复杂。
近似结果:实时视图可能不如批处理视图精确(例如,对短暂时间窗口的统计)。
技术选型:
Apache Storm, Apache Flink, Apache Samza, Kafka Streams
输出:实时视图,例如过去5分钟的页面点击量。
3. 服务层
职责:响应查询,它需要合并来自批处理层和速度层的结果,提供一个完整的数据视图。
工作方式:
对批处理视图进行索引,使其支持低延迟查询。
当查询到达时,服务层同时查询批处理视图(全量精确结果)和实时视图(最新增量结果)。
将两部分结果合并后返回给用户。公式通常为:
查询结果 = 批处理视图(全量) + 实时视图(最新增量)。
技术选型:
doris,clickhouse,Apache Druid, Elasticsearch, Apache HBase, Cassandra
一个简单例子:网站实时访问计数器
假设我们要统计网站总的页面浏览量(PV),并且要求能看到近乎实时的结果。
批处理层:每小时运行一次 Spark 作业,处理过去一小时内所有的访问日志,计算出截止到上一小时的累计 PV,并存入 HBase。
速度层:使用 Flink 实时处理当前的访问日志流,计算从当前小时开始到此刻的增量 PV,并将结果存储在 Redis 中。
服务层 & 查询:
当用户查询“当前总 PV 是多少?”时,服务层会:
从 HBase 中取出最近一个批处理完成时的总 PV(例如,100万)。
从 Redis 中取出本小时内新增的 PV(例如,5000)。
将两者相加(100万 + 5000 = 100.5万)并返回。
最终,用户得到了一个近乎实时(秒级延迟)且最终精确的结果。
Lambda 架构的优点
平衡了性能与准确性:既有批处理保证的准确性,又有速度层提供的低延迟。由于速度层存在数据乱序和延迟到达的问题,可能导致计算结果的误差。
容错性好:批处理层基于不可变数据和分布式计算,易于回滚和重算。即使速度层出错,丢失的也只是少量实时数据,最终会被批处理层修正。
可扩展性强:每层都可以独立水平扩展。
查询灵活性:可以查询全量历史数据,也可以查询最新的实时状态。
Lambda 架构的缺点(也是其备受争议之处)
系统复杂性高:需要开发和维护两套独立的、逻辑相似但技术栈不同的数据处理管道(批处理和流处理),带来双倍的开发和运维成本。
代码重复:相同的业务逻辑需要在批处理和流处理中分别实现,尽管有像 Apache Beam 这样的框架试图用同一套 API 解决,但在实践中仍有差异。
最终一致性:查询结果是批处理视图和实时视图的合并,这意味着在数据完全进入批处理层之前,结果可能不是“最终精确”的。
资源消耗大:同一份数据被计算了两次(批处理和流处理),存储了多次(原始数据、批处理视图、实时视图),资源利用率不高。
演进与替代方案
由于上述缺点,特别是复杂性,业界提出了其演进和替代方案:
Kappa 架构:
核心思想:只用一套流处理系统。将所有数据(历史和实时)都视为流。
实现:使用一个支持高吞吐、低延迟、精确一次处理且能保存足够长时间历史数据的流处理引擎(如 Apache Flink, Kafka + Streams)来处理所有计算。
当需要重新计算时:不是启动批处理作业,而是启动一个新的流处理作业,从历史数据的源头(通常是 Kafka)重新消费并计算,输出到新的表/视图中,完成后将查询指向新视图。
优点:架构极大简化,一套代码,一套系统。
“Lambda + Kappa”混合架构:在实践中,很多公司根据业务场景混合使用。例如,对准确性要求极高的核心报表使用批处理,对实时监控使用流处理。
现代流处理引擎的崛起:以 Apache Flink 为代表的现代流处理框架,提供了状态管理、事件时间处理、精确一次语义等强大功能,使得用一套流处理系统同时满足实时和准实时批处理需求成为可能,大大推动了 Kappa 架构的落地。
总结
何时选择 Lambda 架构?
当你的业务对历史数据的计算准确性有极端要求(如金融对账、合规报表),并且实时性也是明确需求时,Lambda 架构仍然是一个经过验证的稳健选择。但随着像 Flink 这样的流处理技术日益成熟,Kappa 架构或混合架构已成为目前更多新系统的首选,因为它极大地降低了复杂性和维护成本。
评论