数据仓库主要的建模方法为:维度建模和实体关系建模(ER建模)。其他还有ER模型的衍生模型:Data Vault 模型和Anchor 模型,实际工作中很少使用。
维度建模
🎯 概念描述:
维度建模由 Ralph Kimball 在《数据仓库工具箱》一书中提出的建模方法,面向分析场景,核心思想是以业务过程为中心,构建事实表与维度表的关联模型,目的是简化数据分析复杂度、提升查询效率,适配业务人员和分析师的分析习惯。
事实表:用于存储业务过程中的事实或度量,比如销售金额、订单数量等,它包含了与业务过程相关的数值型数据,每行代表一个业务事件。
维度表:描述业务过程上下文环境,它提供了分析事实的“视角”或“筛选条件”,回答了“谁、什么、何时、何地、为何”等问题。例如时间、产品、客户等。
维度建模方法的提出主要是为了应对分析决策场景,因为维度建模在分析需求中更易用,并且在大规模查询中的性能更强。
经典模型:星型模型与雪花模型
1. 星型模型
一个中心的事实表,周围连接着多个维度表。
维度表直接与事实表相连,不进行规范化(维度表是“宽表”,可能包含冗余数据,如产品分类直接放在产品维度表中)。
优点:结构最简单,查询时连接少,性能最高,最易于理解。
缺点:存在数据冗余。
2. 雪花模型
在星型模型的基础上,将维度表进一步规范化,拆解成多层。
例如,产品维度表不直接包含“产品分类”,而是通过一个“分类ID”关联到另一个“产品分类维度表”。
优点:减少了数据冗余,更符合数据库设计规范。
缺点:结构复杂,查询时需要更多的表连接,对性能有负面影响,对业务用户不友好。
实际选择:绝大多数数仓项目(特别是基于Hive/MPP的现代数仓)都优先使用星型模型,因为存储成本已不是首要问题,而查询性能和易用性至关重要。雪花模型仅在维度非常复杂或业务有特殊规范化要求时使用。
🎯 维度建模的步骤:
选择业务过程
确定需要建模的业务过程,例如用户行为(如曝光点击)、销售订单等。业务过程是业务活动的一个明确的操作单元,是维度建模的起点。
声明粒度
粒度指表中一行数据所代表的细节程度。粒度越细,数据越详细;粒度越粗,数据越汇总。在设计事实表之前,需要明确事实表的粒度,例如是按每笔交易记录,还是按每天的汇总数据记录。
确定维度
找出与业务过程相关的所有维度,如时间、地区、产品、客户等。每个维度都有一个唯一的主键,用于关联事实表。维度表可以包含描述该维度的各种属性,如产品维度表可以包含产品名称、产品类别、产品价格等属性。
确定事实
确定业务过程中的数值型字段,也就是事实。事实通常是数值型的,并且是可加的,例如销售金额、销售数量等。将这些事实存储在事实表中,并通过外键与维度表关联。
🎯 维度建模案例:
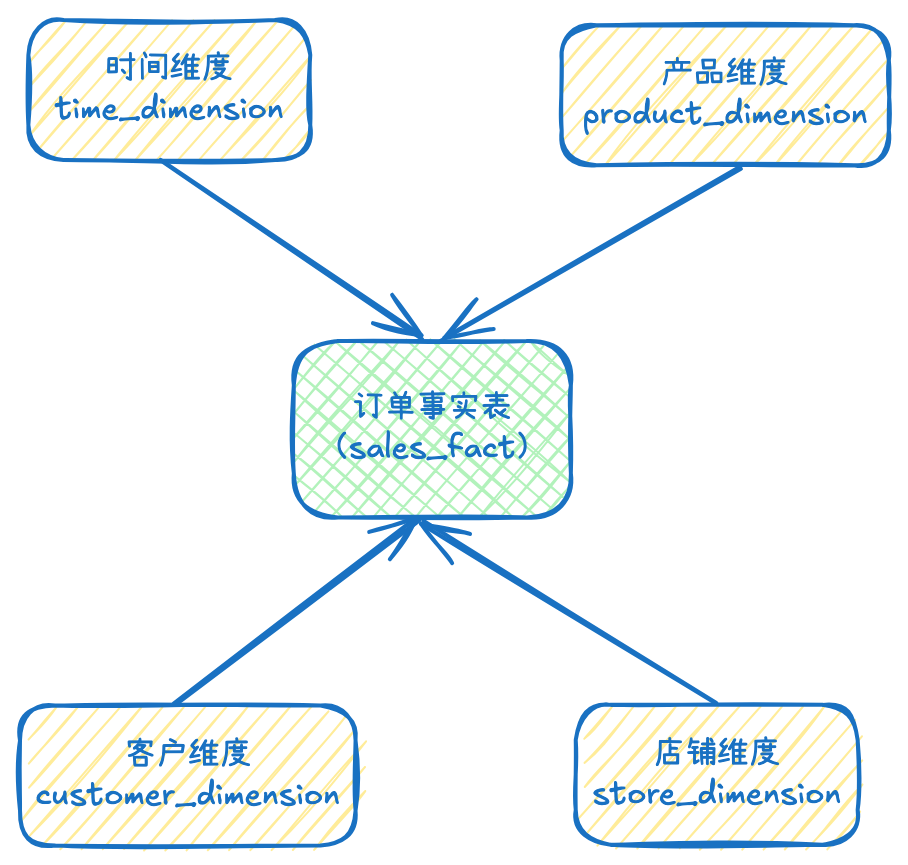
以电商中的订单业务为例,下面进行维度建模。
✨选择业务过程
本次选择电商的订单业务作为建模的业务过程。
✨声明粒度
事实表的粒度为订单id+产品id,即事实表的每行数据中订单id和产品id都是不同的。
✨确定维度
时间维度:包含日期、年份、季度、月份、星期等属性。
产品维度:包含产品 ID、产品名称、产品类别、产品价格等属性。
客户维度:包含客户 ID、客户姓名、客户性别、客户所在地区等属性。
店铺维度:包含店铺 ID、店铺名称、店铺所在地区等属性。
✨确定事实
销售金额:每笔订单的销售总金额。
销售数量:每笔订单中销售的产品数量。
以下是简单的 SQL 代码示例,用于创建上述维度表和事实表:
-- 创建时间维度表
CREATE TABLE time_dimension (
date DATE,
year INT,
quarter INT,
month INT,
week INT
);
-- 创建产品维度表
CREATE TABLE product_dimension (
product_id VARCHAR(50),
product_name VARCHAR(100),
product_category VARCHAR(50),
product_price DECIMAL(10, 2)
);
-- 创建客户维度表
CREATE TABLE customer_dimension (
customer_id VARCHAR(50),
customer_name VARCHAR(100),
customer_gender VARCHAR(10),
customer_region VARCHAR(50)
);
-- 创建店铺维度表
CREATE TABLE store_dimension (
store_id VARCHAR(50),
store_name VARCHAR(100),
store_region VARCHAR(50)
);
-- 创建订单事实表
CREATE TABLE sales_fact (
order_id INT,
product_id INT,
order_date INT,
customer_id INT,
store_id INT,
sales_amount DECIMAL(10, 2),
sales_quantity INT
);
通过以上步骤和实例,对维度建模有一个基本的了解,上面的模型是一个典型的星型模型。在实际应用中,需要根据具体的业务需求和数据特点进行灵活调整。
ER建模(实体关系建模)
🎯 概念描述:
ER建模是基于实体、属性、关系三大核心要素的结构化建模方法,核心目标是清晰描述业务数据的内在关联,保证底层数据的完整性和一致性。它基于关系数据库的设计理论,以减少数据冗余、保证数据一致性为主要目标,遵循一定的范式规则:如第一范式(1NF)、第二范式(2NF)、第三范式(3NF)等。
🎯 数据库三范式:
第一范式:数据库表中的每一列都是不可分割的原子值,即同一列中不能包含多个值或重复属性。
第二范式:在满足1NF的基础上,非主属性完全依赖于主键,而非主键的一部分(针对复合主键)。
第三范式:在满足2NF的基础上,非主属性不传递依赖于主键,即属性与主键字段之间无依赖关系。
🎯 设计步骤:
实体识别:从业务中提取实体,如客户、订单、产品等。
属性定义:为每个实体定义属性,如客户的姓名、年龄、地址等。
关系确定:分析实体之间的关系,如一对一、一对多、多对多关系。
范式化处理:对数据模型进行范式化,消除数据冗余和异常。
🎯 优缺点:
优点:数据冗余小,数据一致性高,便于数据的维护和更新。
缺点:查询性能相对较低,因为需要进行大量的表连接操作;模型设计和开发的复杂度较高。
适用场景:适用于对数据一致性要求较高、数据更新频繁的场景,如在线事务处理(OLTP)系统。
🎯 ER建模案例:
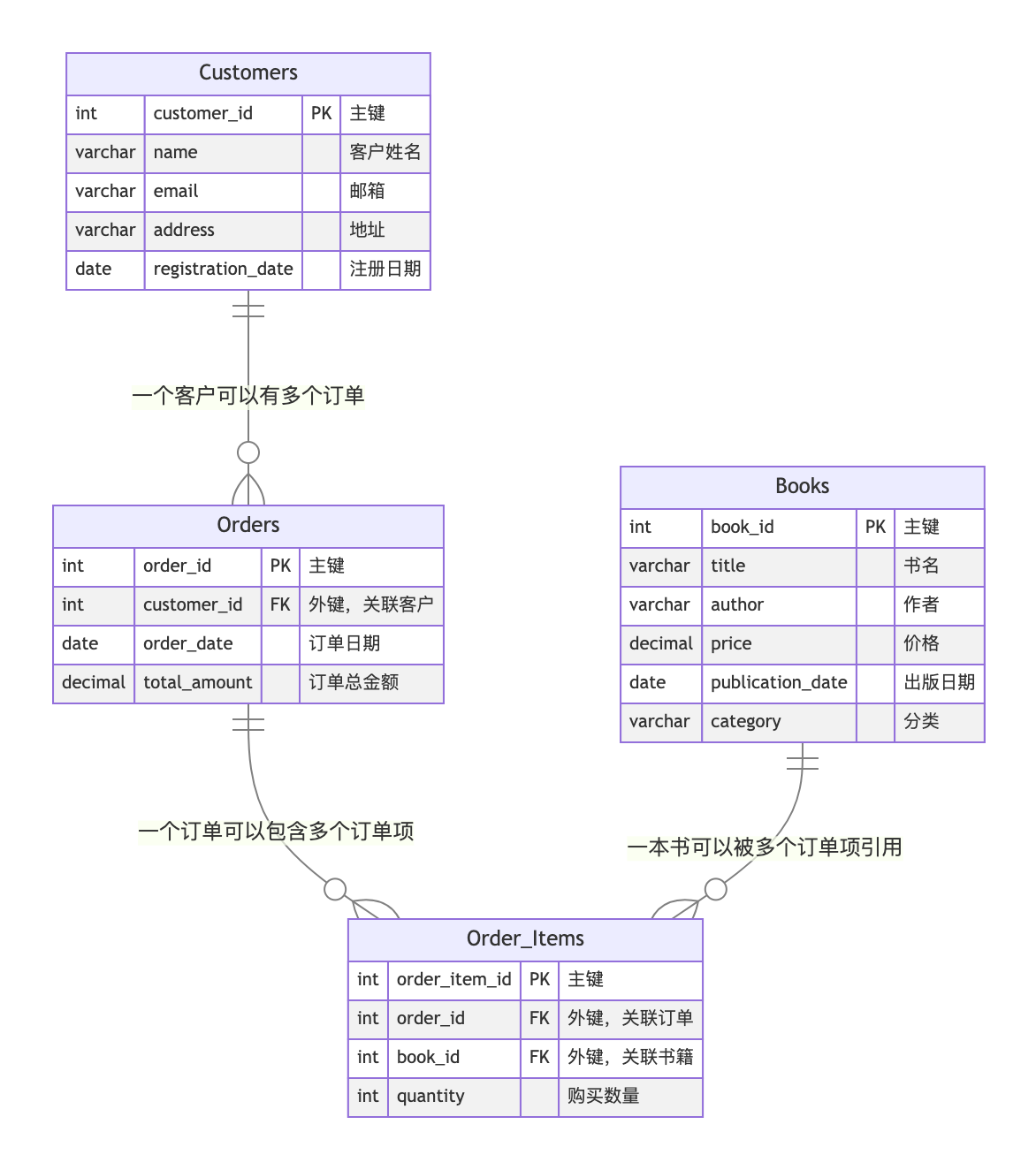
以下是一个使用 ER 建模方法的案例,以在线书店为例。
ER 模型描述:
实体、属性:
订单(Orders):包含订单的基本信息,如订单日期、总金额等,客户id等。
书籍(Books):包含书籍的基本信息,如标题、作者、价格等。
客户(Customers):包含客户的基本信息,如姓名、邮箱、地址等。
订单商品(Order_Items):包含订单中的商品信息,如订单id、书籍id、数量等。
关系:
客户 - 订单:一个客户可以下多个订单,是一对多的关系。
订单商品:一个订单可以包含多本书籍,是一对多的关系。
模型设计
模型关系图
评论