
Kappa架构概述
Kappa 架构是作为对经典的 Lambda 架构 的反思和简化而提出的。它的核心思想是:用一个统一的流处理系统来处理所有数据,无论是实时数据还是历史数据,从而消除 Lambda 架构中复杂的“批处理层”和“服务层”的双重维护。
1. Kappa 架构诞生的背景:Lambda 架构的挑战
要理解 Kappa,必须先了解 Lambda。Lambda 架构包含三层:
批处理层(Batch Layer): 处理全量历史数据,生成批处理视图。高延迟、高准确性。
速度层(Speed Layer): 处理实时增量数据,生成实时视图。低延迟、近似结果。
服务层(Serving Layer): 合并批处理视图和实时视图,提供统一的查询接口。
Lambda 架构的问题:
系统复杂性高: 需要开发、维护两套逻辑相似但运行在不同引擎(如 Hadoop MapReduce/Spark 和 Storm/Flink)上的代码。
运维负担重: 需要管理两套系统,确保数据一致性、资源调度等。
数据口径可能不一致: 由于两套逻辑,在合并视图时可能出现偏差。
2. Kappa 架构的核心思想
为了解决上述问题,Jay Kreps 在 2014 年提出了 Kappa 架构。其核心原则是:
“Everything is a stream.”(一切皆流)
它将所有数据都视为流:
实时数据 自然就是数据流。
历史数据 被视为存储在持久化存储(如 Kafka)中的“流”,通过从头开始重新消费(Replay)来重新计算。
3. Kappa 架构的工作流程
下图清晰地展示了 Kappa 架构的核心数据流与处理过程:
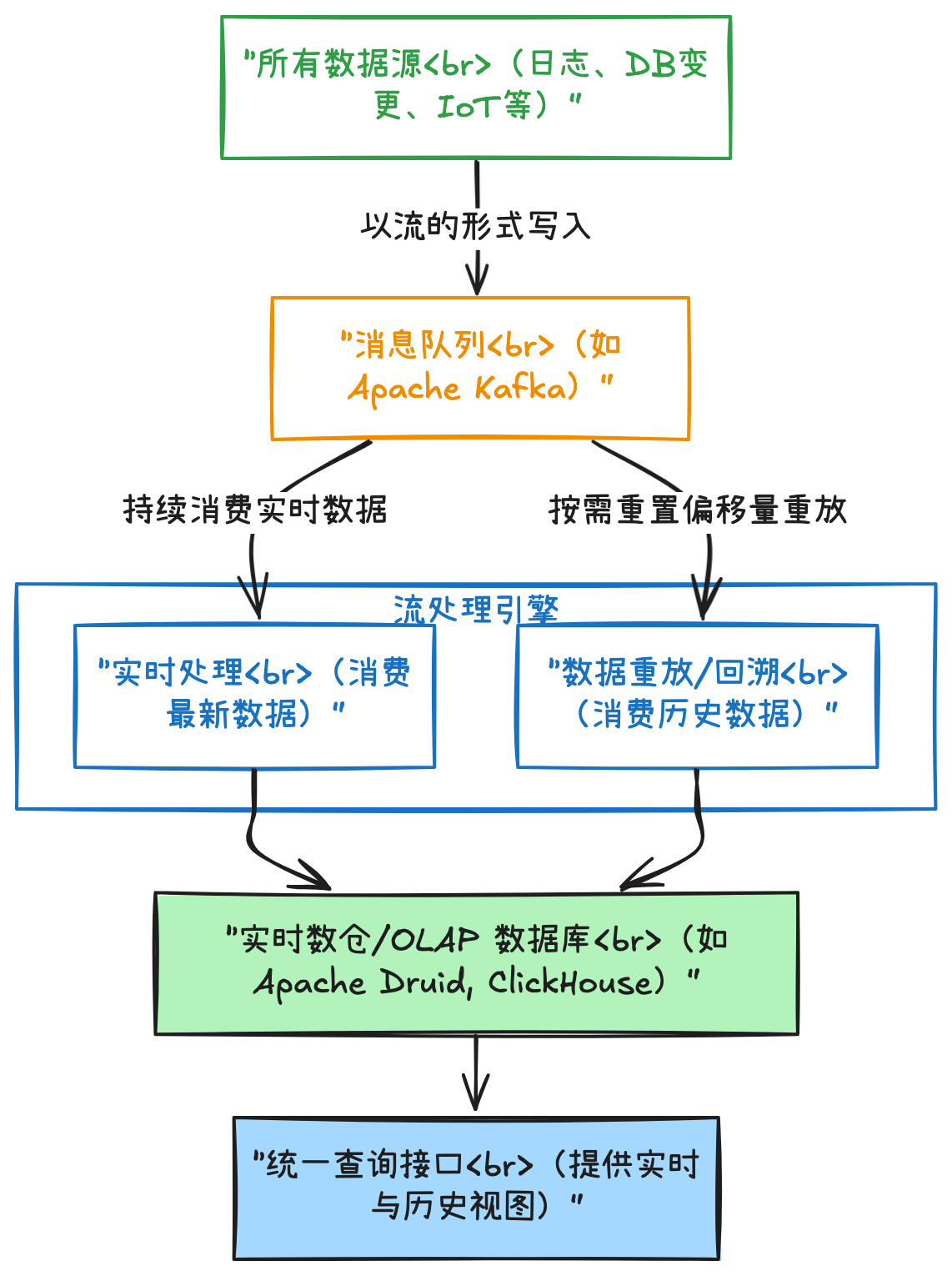
如上图所示,其流程可以概括为以下几个关键步骤:
第一步:统一的数据入口
所有数据(业务日志、数据库变更 CDC、传感器数据等)都被作为流式数据,直接写入一个高吞吐、可持久化、支持重放的消息队列(如 Apache Kafka)。这是 Kappa 架构的基石,它成为了一个“不可变的原始数据日志”。
第二步:单一的处理层
只有一个流处理引擎(如 Apache Flink, Apache Spark Streaming, ksqlDB)来消费 Kafka 中的数据。
对于实时数据: 处理引擎持续消费 Kafka 队列尾部的数据,进行实时计算,并将结果输出到下游的数据库或数据湖中。
对于历史数据重新计算(关键!): 当业务逻辑变更,或需要修复历史数据时,Kappa 架构的做法是:
a. 启动一个新的流处理作业实例。
b. 从 Kafka 的起始偏移量(或某个更早的时间点)开始重新消费全量历史数据。
c. 用新的业务逻辑处理这些数据,并将新的结果写入新的输出表或版本化存储中。
d. 一旦新的作业追上实时进度,就将查询流量切换到新的结果表上,并停止旧作业。
第三步:统一的输出与服务
处理后的结果写入统一的可查询存储,如:
实时 OLAP 数据库: ClickHouse, Apache Druid, Pinot。
数据湖/数据湖仓: Apache Iceberg, Delta Lake, Hudi(支持流式 Upsert)。
键值存储或搜索引擎: 用于点查。
所有查询(无论是查最新状态还是历史分析)都指向这个统一的存储层。
4. Kappa 架构的优势
架构极大简化: 只需要维护一套流处理系统和代码,降低了开发和运维复杂度。
数据一致性有保障: 实时和历史处理使用同一套逻辑,避免了 Lambda 架构中可能出现的口径不一致问题。
真正的实时性: 从数据产生到可查询的延迟极低。
灵活的数据重演: 通过重放 Kafka 中的数据,可以方便地修复数据、回溯历史或测试新逻辑。
5. Kappa 架构的挑战与局限性
消息队列的长期存储成本: Kafka 等系统虽然支持长期存储,但成本远高于对象存储(如 S3)。通常需要制定合理的数据保留策略(如 30-90 天),更久的数据需要归档到成本更低的存储中,重放时会变得复杂。
流处理引擎的精确一次语义和状态管理: 长时间窗口(如月、年)的聚合计算在流处理中挑战较大,需要强大的状态管理和容错机制(如 Flink 的 Checkpoint)。
数据回溯的耗时与资源消耗: 重新处理数 TB 甚至 PB 级的历史数据可能非常耗时,并消耗大量计算资源。
高吞吐批处理场景: 对于单纯的、不需要低延迟的超大规模历史数据分析,经典的批处理引擎可能仍然更高效、成本更低。
6. 现代演变与最佳实践
纯粹的 Kappa 架构和 Lambda 架构现在更多是两种思想。在实践中,流批一体 的引擎和 数据湖仓 的出现,正在融合两者的优点,形成更灵活的架构:
流批一体的处理引擎: 如 Apache Flink 和 Apache Spark,它们可以用同一套 API 编写作业,引擎本身决定以流或批的方式执行。这简化了 Kappa 架构中“一套代码”的实现。
数据湖仓作为统一存储层: 将 Kafka 中的原始数据定期或实时地落地到 Apache Iceberg/Hudi/Delta Lake 格式的数据湖中。这解决了长期存储成本问题:
流处理作业 消费 Kafka 处理实时数据。
批处理作业 或 同一个流批一体作业 可以读取数据湖中的全量数据进行回溯或补充计算。
湖仓提供统一的元数据管理和 ACID 事务,保障数据一致性。
“可重放的”数据湖作为 Source: 现代数据湖格式本身也支持“增量读取”,可以像流一样被消费。这使得架构可以演变为:数据湖作为唯一的可信数据源,流和批作业都从其中读取数据。
总结
结论: Kappa 架构是一种优雅的架构范式,特别适合实时性要求高、业务逻辑变更相对频繁、团队希望降低系统复杂度的场景。随着流批一体技术和数据湖仓的成熟,采用 Kappa 架构的思想,并利用现代数据栈进行务实改造,已成为当前构建数据平台的主流方向。在选择时,需要根据数据的规模、实时性要求、团队技能和成本预算进行综合权衡。
评论