一、引言
1.1 数仓的作用
现在正处在一个数据驱动决策的时代,数据仓库作为管理数据和提供数据支持的工具,在企业决策中发挥着越来越重要的作用。
提升决策效率:企业有很多业务系统,产生各种各样的数据,数据仓库能将这些分散的数据进行整合,形成统一的数据模型。分析师与决策者无需在繁杂的数据源间反复切换查询,通过数据仓库即可快速获取所需数据,大大缩短决策周期。例如,在快消品行业,市场部门在制定促销活动策略时,可从数据仓库迅速获取销售、库存、市场调研等多维度数据,快速分析出最佳促销方案,把握稍纵即逝的市场机遇。
增强决策精准度:数据仓库可以保证数据质量。基于高质量的数据进行分析,能为决策提供可靠数据支持。以金融机构的信贷审批为例,数据仓库整合了客户的信用记录、资产状况、还款能力等多源数据,通过对这些数据的深度挖掘与分析,银行可以更精准地评估客户的信用风险,降低不良贷款率,提升信贷决策的质量。
助力业务创新:通过对历史数据的分析,企业可以发掘新的业务模式与机会。例如,电商平台借助数据仓库分析用户的浏览、购买行为数据,挖掘潜在需求,推出个性化推荐服务与创新性的营销活动,拓展业务边界,提升用户体验与市场竞争力。
提供竞争优势:企业可以基于数据仓库的数据,分析市场趋势、客户偏好变化,及时调整战略,推出更符合市场需求的产品与服务,从而在竞争中脱颖而出。例如,在智能手机市场,手机厂商通过数据仓库分析消费者对手机功能、外观、价格等方面的需求数据,以及竞争对手的产品策略,快速推出具有竞争力的新品,抢占市场份额。
二、数据仓库基础
2.1 数据仓库定义
数据仓库之父 Bill Inmon 的经典定义:“数据仓库是一个面向主题的、集成的、稳定的且随时间变化的数据集合,用于支持管理决策。”
面向主题(如销售主题、客户主题、订单主题等,围绕业务主题组织数据)、集成(整合来自不同数据源的数据)、稳定(数据存储后一般不修改)、随时间变化(保存历史数据,并且新增数据)
2.2 数据仓库与数据库对比
数据库:主要用于事务处理(OLTP),支持日常业务操作,强调数据的实时性与事务完整性,数据结构为满足频繁的增删改查操作而设计,数据粒度较细
数据仓库:用于分析处理(OLAP),支持决策制定,注重数据的集成与历史数据的存储,数据结构按主题组织,数据粒度较粗
例如两者在银行系统中的应用差异:数据库用于客户存取款、转账等操作;数据仓库用于分析客户信用、贷款风险等
三、数据仓库架构
3.1 体系架构概述
经典的三层架构图:数据源层、数据存储层、数据分析层,如下图所示:
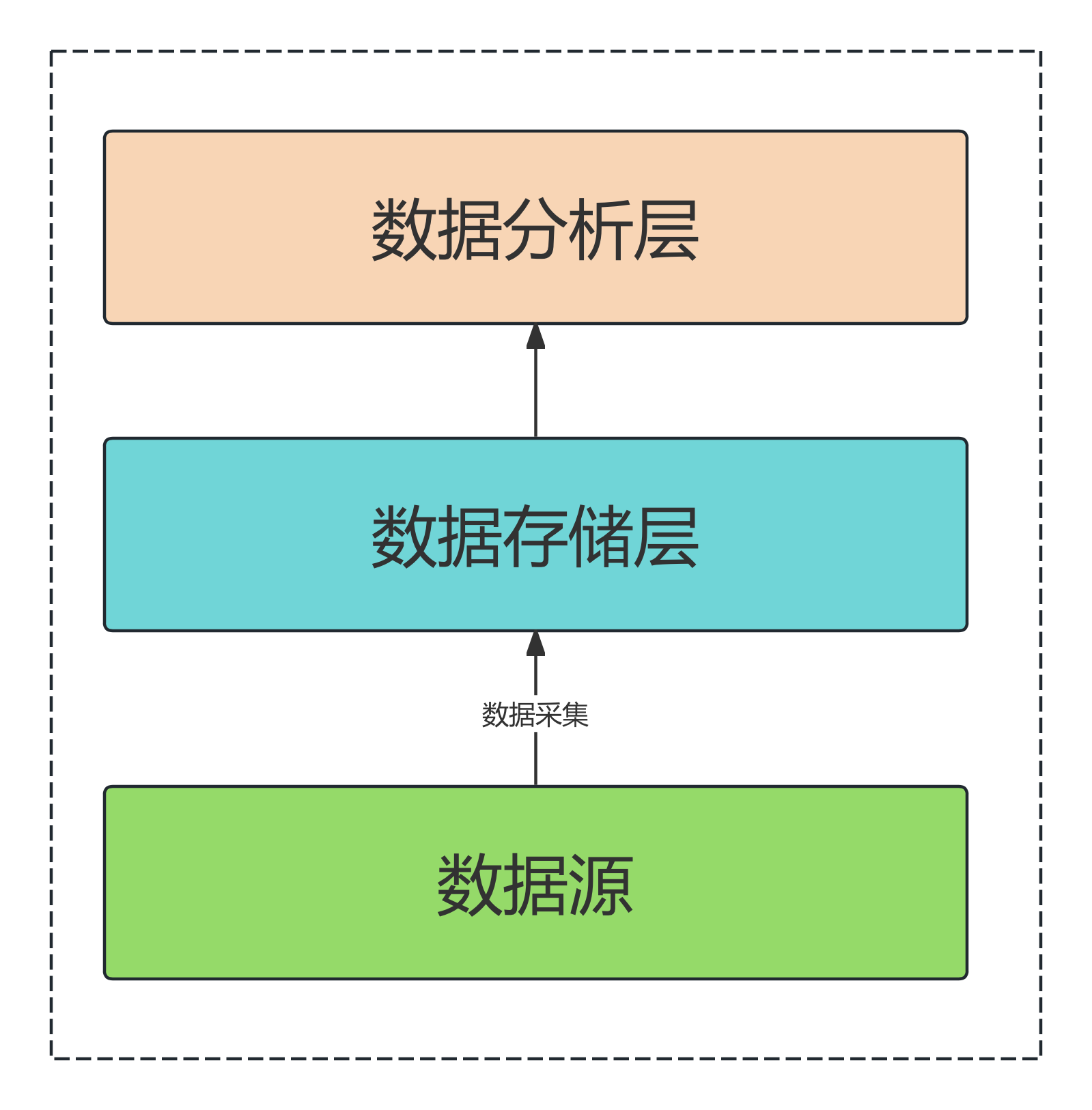
数据源层:包括各内部业务系统数据库(如 mysql、postgresql等)、日志数据、excel等
数据存储层:数据仓库核心,这一层会对数据划分主题,并进行数据分层,如:ODS(原始数据)、DWD(明细数据)、DWA/DM(数据集市)、APP(应用层)等
数据分析层:OLAP 分析、数据报表生成,供用户进行数据分析
3.2 关键概念和组件
ETL: Extract(抽取)、Transform(转换)、Load(加载)过程,如从多个数据库抽取数据,清洗异常值、转换数据格式后加载到数据仓库
数据建模:选择合适的数据建模方法、合适的数据模型(如星型模型、雪花模型),主题的划分、数据分层的方法,模型的命名规范等。
元数据管理系统:记录元数据信息(如数据结构、存储信息、数据血缘等),帮助理解数据含义、追踪数据上下游关系。
指标管理系统:管理常用指标,控制指标录入流程,提供指标接口
数据质量管体系:数据完整性、准确性、一致性和时效性。
数据安全管理系统:数据模型保密等级划分,数据加密,权限控制
数据应用:依托于数据平台、BI分析系统、数据推送服务
四、数据仓库构建流程
4.1 需求分析
了解业务:梳理业务系统模块,理解各模块功能
了解需求:与业务部门沟通,明确分析目标与需求,确认数据支持的方式。如销售部门需分析各地区产品销售趋势,确定需要哪些数据、分析维度、以什么形式输出数据
建立需求文档:包含业务理解、需求目标、数据需求清单、使用场景等
4.2 模型设计
概念建模:基于对业务和需求的理解,确定主题域(如客户、合同、订单、业绩等),梳理业务过程
逻辑建模:选择建模方法、设计数据分层、梳理业务过程设计事实表和维度表。
物理建模:确定存储介质、确定表结构、分区等。
4.3 模型开发
开发模型:根据模型设计,在数据仓库中创建模型,并配置调度任务完成数据处理流程
模型测试:保证数据质量,比如数据的完整性、准确性、一致性和时效性
4.4 监控和报警
建立监控机制:监控数据更新、验证数据质量,当发现数据质量问题时及时报警解决
五、数据仓库应用案例
某旅游咨讯服务公司流量数据仓库设计案例
目标:构建流量数仓,支持每日用户访问量统计、近30天访问趋势分析,并通过BI仪表盘实现可视化。
需求分析
1. 核心业务问题
观测指标:
每日PV(页面浏览量)、UV(独立访客数)
近30天访问趋势
不同设备类型的日访客情况
不同城市的日访客情况
2. 业务梳理
梳理一下流量数据的产出流程,如典型的流程如下:
APP/PC -> 用户行为数据 -> 日志服务器 -> 日志文件
再梳理一下可能用到的属性信息:
如用户属性数据(mysql)、广告投放属性等
模型设计
主题划分
这个案例只关注流量数据,所以只有一个主题:user_behavior,英文缩写:ub
数仓分层
业务过程梳理
逻辑设计:
(1)明细层(DWD)
事实表设计
flow.dwd_ue_page_access_di(页面访问事实表)
CREATE TABLE flow.dwd_ue_page_access_di (
log_id STRING COMMENT '日志唯一ID',
user_id STRING COMMENT '用户ID(未登录用户为设备ID)',
session_id STRING COMMENT '会话ID',
page_id string comment '页面唯一标识',
page_url STRING COMMENT '页面URL',
event_type string comment '事件类型:click,show',
event_time TIMESTAMP COMMENT '事件时间',
city_code STRING COMMENT '访问城市',
city_name STRING COMMENT '城市名称',
device_type STRING COMMENT '设备类型(PC/iOS/Android)',
referrer STRING COMMENT '流量来源(直接访问/广告ID/媒体)',
channel_name STRING COMMENT '渠道名称',
stay_duration INT COMMENT '页面停留时长(秒)'
)
PARTITIONED BY (dt STRING) -- 按天分区
STORED AS ORC; 维度表
dim.dim_ad_channel_df(广告渠道维度表)
CREATE TABLE dim.dim_ad_channel (
ad_id STRING COMMENT '广告ID',
channel_name STRING COMMENT '渠道名称',
campaign_name STRING COMMENT '广告活动名称',
start_date DATE COMMENT投放开始时间,
end_date DATE COMMENT投放结束时间
)
STORED AS ORC;dim.dim_city_df(城市维度表)
CREATE TABLE dim.dim_city (
city_code STRING COMMENT '城市编码',
city_name STRING COMMENT '城市名称',
province STRING COMMENT '所属省份',
region STRING COMMENT '大区(华东/华北等)'
)
STORED AS ORC;(2)聚合层(DWA)
dwa.dwa_ue_daily_access_merge_di(日粒度聚合表)
CREATE TABLE dwa.dwa_ue_daily_access_di (
user_id STRING COMMENT '用户ID(未登录用户为设备ID)',
dt string COMMENT '统计日期',
page_id string comment '页面唯一标识',
city_name STRING COMMENT '城市名称',
device_type STRING COMMENT '设备类型',
event_type string comment '事件类型:click,show',
channel_name STRING COMMENT '渠道名称'
)
PARTITION BY (dt STRING) -- 按天分区
STORED AS ORC;(3)应用层(APP)
CREATE TABLE app.app_ue_daily_access_di (
dt string COMMENT '统计日期',
city_name STRING COMMENT '城市名称',
device_type STRING COMMENT '设备类型',
pv BIGINT COMMENT '页面浏览量',
uv BIGINT COMMENT '独立访客数'
)
PARTITION BY (dt STRING) -- 按天分区
STORED AS ORC;模型开发
建模过程可以基于spark sql、hql或者使用原始spark api、mapreduce进行开发,并通过调度系统定时调度执行。
BI分析系统与仪表盘设计
数据模型建好以后,下一步需要设计数据应用方案,这一步需要数据基建的配合,比如一般的多维分析场景或者固定指标的看板场景,需要bi分析系统的支持;再比如高层汇报或者对外提案则需要定制开发;再如特定节点的活动推送场景,则需要将数据直接推送到特定群组。不同的场景需要不同的基建支撑。
对于当前这个分析场景,服务对象是分析师和客户增长团队,那么可以将每天的访问量、访问趋势、以及其他多维分析的结果固化到仪表盘中,用于分析决策。
最终成果
通过日常流程数据的观测可以及时发现客户流失或者异常波动情况,各业务部门及时归因及时干预,防止企业损失。
评论