
数据仓库是一个体系庞大的领域,拥有许多专业名词术语。这里系统性地梳理和解释最核心、最常用的术语。
分类 | 名词 | 解释 | 例子 |
|---|---|---|---|
维度建模 | 业务模块 | 业务模块是指按照企业不同业务领域或功能划分的数据组织单元。它反映了企业在实际运营中的核心业务流程和主题,是构建数据仓库逻辑模型和物理模型的重要依据。 | 比如销售模块、财务模块、客户关系管理模块 |
主题域 | 主题域是从分析的角度对数据进行分类,代表企业中一个核心业务领域或分析主题,如“销售”、“财务”、“客户”、“供应链”等。它是面向业务过程和分析需求的抽象。 | 业绩主题域、用户主题域 | |
数据域 | 从技术或数据治理视角,指具有相同业务含义、数据结构或管理规则的一组数据集合。例如“客户信息域”、“产品数据域”、“交易数据域”等。与主题域接近,但更强调数据资产的归属和管理边界。 | 交易域、用户域 | |
业务过程 | 业务过程是指企业中可被度量、可重复发生的、具有明确时间点的关键业务活动。业务过程是一个不可拆分的行为,表示用户的动作,比如下单、评论、点赞等。 | 下单、支付 | |
粒度 | 粒度是指事实表中每一行所代表的业务细节程度,比如广告点击的每一行代表一个用户对一条广告的一次点击。 | 电商销售、银行交易 | |
维度 | 是描述业务过程上下文的环境,用于回答 “谁、什么、何时、何地、为什么、如何” 等分析问题。比如客户、产品、时间、组织架构。 | 日期维度、品牌维度、用户维度 | |
事实 | 事实表中的一行记录所代表的业务过程的可量化字段,通常以数值字段形式存在,是可加、可计算的原始数据。 | 销售金额、购买数量 | |
度量 | 基于一个或多个事实(有时结合维度逻辑)定义的可被聚合或计算的业务指标。 | 总销售额:sum(sales_amount) 订单数:count(distinct order_id) 客单价:sum(sales_amount) / count(distinct order_id) | |
属性 | 维度属性是维度表中的字段,用于描述业务过程的特征或上下文信息。它们是分析事实数据的“标签”或“分类依据”,让冰冷的数字(如销售额、点击量)具备业务意义。 | 客户的“性别”、“会员等级” 产品的“品牌”、“品类” | |
指标 | 是衡量企业业务运行状况、支持决策分析的核心量化依据。它是从业务需求出发,基于底层数据模型(尤其是事实表中的“事实”)加工计算得出的标准化、可复用、有明确业务含义的数值。 | 订单数、销售额、点击次数 | |
原子指标 | 原子指标是最细粒度、不可再拆分的业务度量,代表一个具体的业务动作或结果。 | 支付金额、下单次数、页面浏览量(PV)、用户注册数 | |
派生指标 | 在原子指标的基础上,加上业务限定条件(如时间周期、维度、业务场景等)形成的具有具体业务含义的指标。 | 近30天新用户的支付金额 2025年Q4 iOS端下单次数 上周华东地区的页面浏览量 | |
复合指标 | 由多个原子指标或派生指标通过数学运算(加减乘除、比率、同比、环比等)组合而成的指标。 | 支付转化率 = 支付订单数 / 下单订单数 客单价 = 支付金额 / 支付人数 | |
时间周期 | 用来限定指标统计的时间范围。 | 最近1天、最近30天、最近一个季度 | |
修饰词 | 用于描述原子指标发生的场景或者满足的条件。 | 新用户、iOS端、华东地区 | |
核心概念 | 数据仓库 | 一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。 | 商业化数仓、流量数仓 |
数据集市 | 数据仓库的一个子集,通常为某个特定部门或主题构建。可以看作图书馆里的一个“专题阅览室”(如“经济图书阅览室”),更小、更专注、建设更快。 | 如销售集市、财务集市 | |
数据湖 | 存储企业所有原始数据(结构化、半结构化、非结构化)的巨型存储库。像一个 “原始湖泊” ,数据以其原始格式保存,直到需要时再进行处理和分析。与数据仓库(清洗后的结构化数据)形成互补。 | 常用工具:hudi、paimon | |
数据湖仓 | 融合了数据湖的灵活性和数据仓库的管理与分析能力的新范式。在数据湖的低成本存储上,实现数据仓库的数据结构、管理和优化功能。 | 基于数据湖构建数据仓库 | |
数据处理 术语 | ETL | 抽取、转换、加载。这是将数据从源系统移动到数据仓库的传统核心流程。
| |
数据管道 | 更广义的概念,指数据从数据源流向目的地(如数据仓库、应用)的自动化流程。ETL/ELT是其中一种具体的数据管道。 | ||
总线矩阵 | 由数据仓库大师Kimball提出的一种标准化、可扩展的架构。通过定义一套企业范围内一致的一致性维度和一致性事实,让不同的数据集市可以像拼乐高一样无缝集成 | 总线矩阵行为业务过程,列为维度 | |
OLAP | olap | 联机分析处理。与OLTP(联机事务处理,如订单录入)相对,是数据仓库的主要操作方式,支持复杂的分析查询、多维度视角和快速响应。 | 适用于分析决策场景 |
多维数据集(数据立方体) | 用于支持联机分析处理(OLAP)的核心结构。它将业务数据组织成便于用户从多个维度进行分析的形式,通常以“立方体”(Cube)的逻辑模型来表示。可以实现极快的钻取、切片、切块、旋转分析。 | 多维数据立方体,二维、三维、四维或者更高维度的立方体。 | |
切片 | 固定某一个维度的单个取值,从 N 维数据立方体中,提取出一个N-1 维的子数据集(子立方体 / 面),本质是 “切出一个维度的某一个截面”。 | 以三维(时间:2025Q1/2025Q2;地区:华东 / 华北 / 华南;产品:家电 / 数码 / 服饰)、度量销售额为例:
| |
切块 | 对一个或多个维度进行取值范围筛选(筛选条件可以是单个值、多个离散值、连续范围),从 N 维数据立方体中,提取出一个与原立方体维度数相同的、体积更小的 N 维子立方体,本质是 “在原立方体中切出一个小的立方体 / 超立方体”。 | 以三维(时间:2025Q1/2025Q2;地区:华东 / 华北 / 华南;产品:家电 / 数码 / 服饰)、度量销售额为例,以下所有操作都是切块:
| |
钻取 | 钻取(Drill)是与切片 / 切块互补的维度粒度垂直操作,核心是改变维度的分析层级粗细,实现数据从汇总到明细或明细到汇总的穿透分析,全程保持数据集的维度数不变,仅改变维度的层级粒度。 钻取分为下钻(Drill Down)和上钻(Drill Up)两个核心方向,二者为逆操作;此外还有跨维度的钻透(Drill Through)(从多维聚合数据钻到原始明细数据),是下钻的延伸 | ||
下钻 | 将某一个 / 多个维度从「高层级粗粒度」钻取到「低层级细粒度」,把聚合的汇总数据拆分为更细粒度的明细数据,粒度变细、数据量变大、分析视角更具体,核心是 “拆解开看细节”。 | 初始视角:时间 = 2025 年(年度)、地区 = 华东(大区)、产品 = 家电(品类)→ 聚合值:2025 年华东家电品类总销售额 5000 万;
| |
上钻 | 将某一个 / 多个维度从「低层级细粒度」钻取到「高层级粗粒度」,把细粒度的明细数据聚合为更粗粒度的汇总数据,粒度变粗、数据量变小、分析视角更宏观,是下钻的逆操作,核心是 “合并起来看整体”。 | 初始细粒度视角:2025Q1/Q2 × 江苏 / 浙江 × 冰箱 / 洗衣机 → 明细销售额(如 Q1 江苏冰箱 200 万、Q1 浙江洗衣机 150 万);
| |
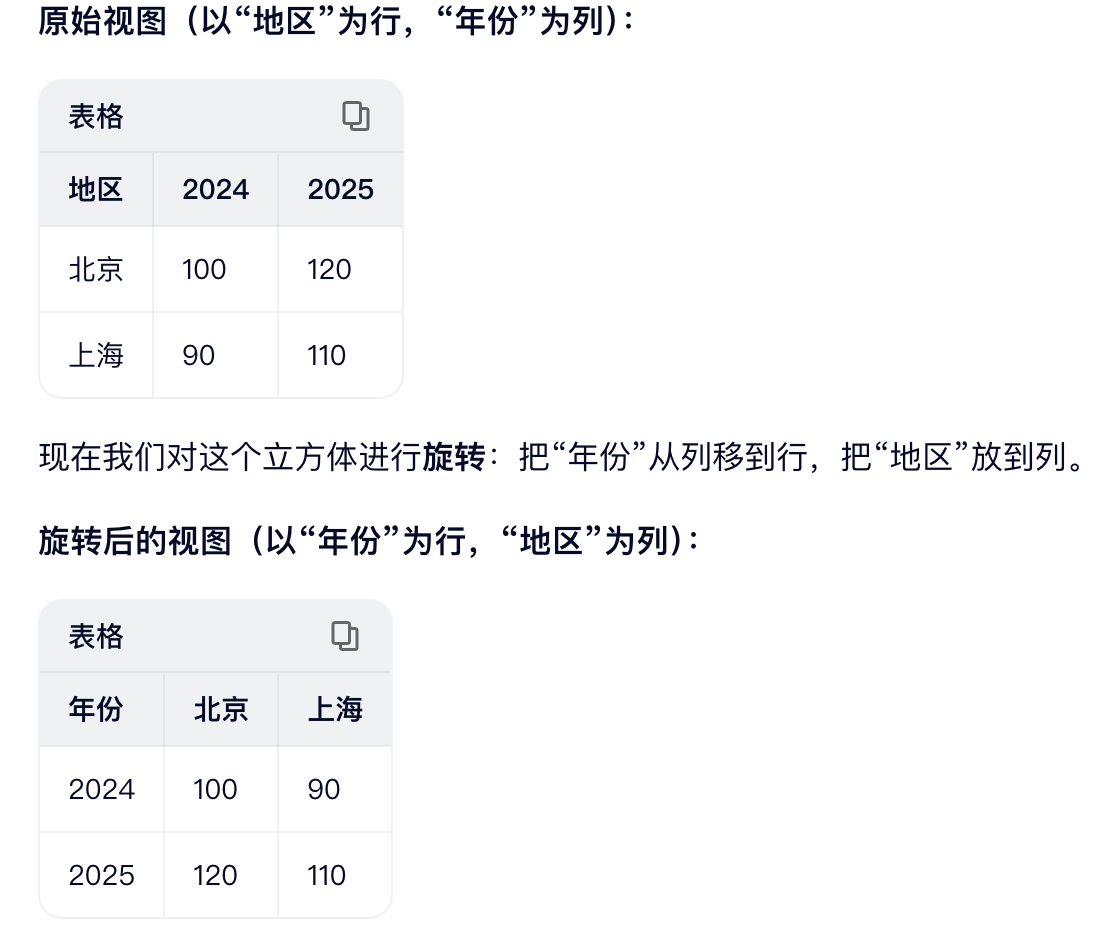
旋转 | 将某个维度从行转为列,或将列转为行,或者改变维度在报表中的展示位置,以获得新的数据视图。 |
| |
物化视图 | 汇总表/预计算表。一个存储了查询结果的数据库对象(如按月、按地区的销售汇总)。当查询命中时,直接返回结果,极大提升复杂聚合查询的速度。 | 当原数据更新时物化视图会自动更新 | |
数据管理 | 元数据 | “关于数据的数据”。描述数据仓库中有什么数据、数据从哪来、如何转换、何时更新等信息。是数据仓库的“地图”和“说明书”,至关重要。 | |
数据血缘 | 追踪数据的来源和变换过程。例如,报表里的一个指标,可以追溯到它最初来自哪个系统的哪个表,经过了哪些处理步骤。用于影响分析、故障排查和数据治理。 | ||
指标管理 | 指标是数据仓库的核心产出物,是业务价值的直接载体。指标管理的目标是统一口径、可追溯、可复用,避免 “数出多门” 的业务争议。 | ||
数据质量 | 数据质量是数据仓库的生命线,直接决定指标分析结果的可信度。其核心目标是保障数据的完整性、准确性、一致性、时效性。 | ||
数据安全 | 数据仓库存储大量敏感数据(如用户手机号、交易金额、企业核心经营数据),数据安全的目标是保障数据在全生命周期内的保密性,同时满足合规要求。 |
评论