
spark内存模型
exector内存模型:
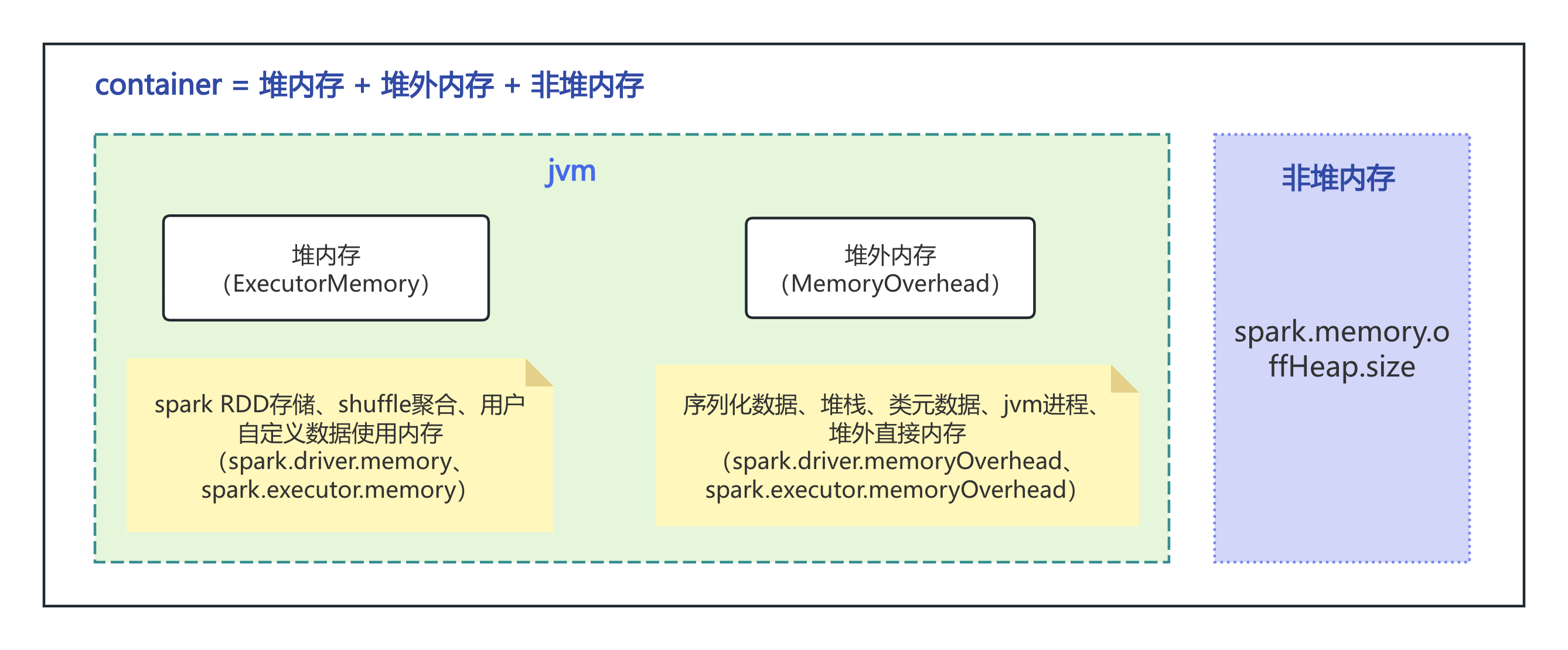
spark执行器包含了堆内存、堆外内存和非堆内存三部分组成。
堆内存:
存储内存(Storage Memory):
作用:主要用于缓存 RDD 数据、广播变量等。当用户使用
cache()或persist()方法对 RDD 进行持久化操作时,相应的数据会存储在存储内存中,方便后续快速访问。例如,在迭代算法中,将一些中间结果的 RDD 存储在存储内存中,能避免重复计算,提高计算效率。参数影响:
spark.storage.memoryFraction决定了存储内存在堆内存中可用于存储和执行的总内存的占比,默认是 0.6(即 60%)。spark.storage.unrollFraction决定了存储内存中可用于展开序列化数据的比例,默认是 0.2。
执行内存(Execution Memory):
作用:为 Spark 任务的执行提供所需的内存,包括各种算子操作时所需的内存,特别是在 Shuffle 操作中,如排序、聚合、连接等操作,都需要执行内存的支持。例如,在 Shuffle 的 Map 端和 Reduce 端进行数据的处理和运算时,会使用执行内存。
参数影响:
spark.shuffle.memoryFraction设定了执行内存在堆内存中可用于存储和执行的总内存的比例,默认是 0.2(即 20%)。
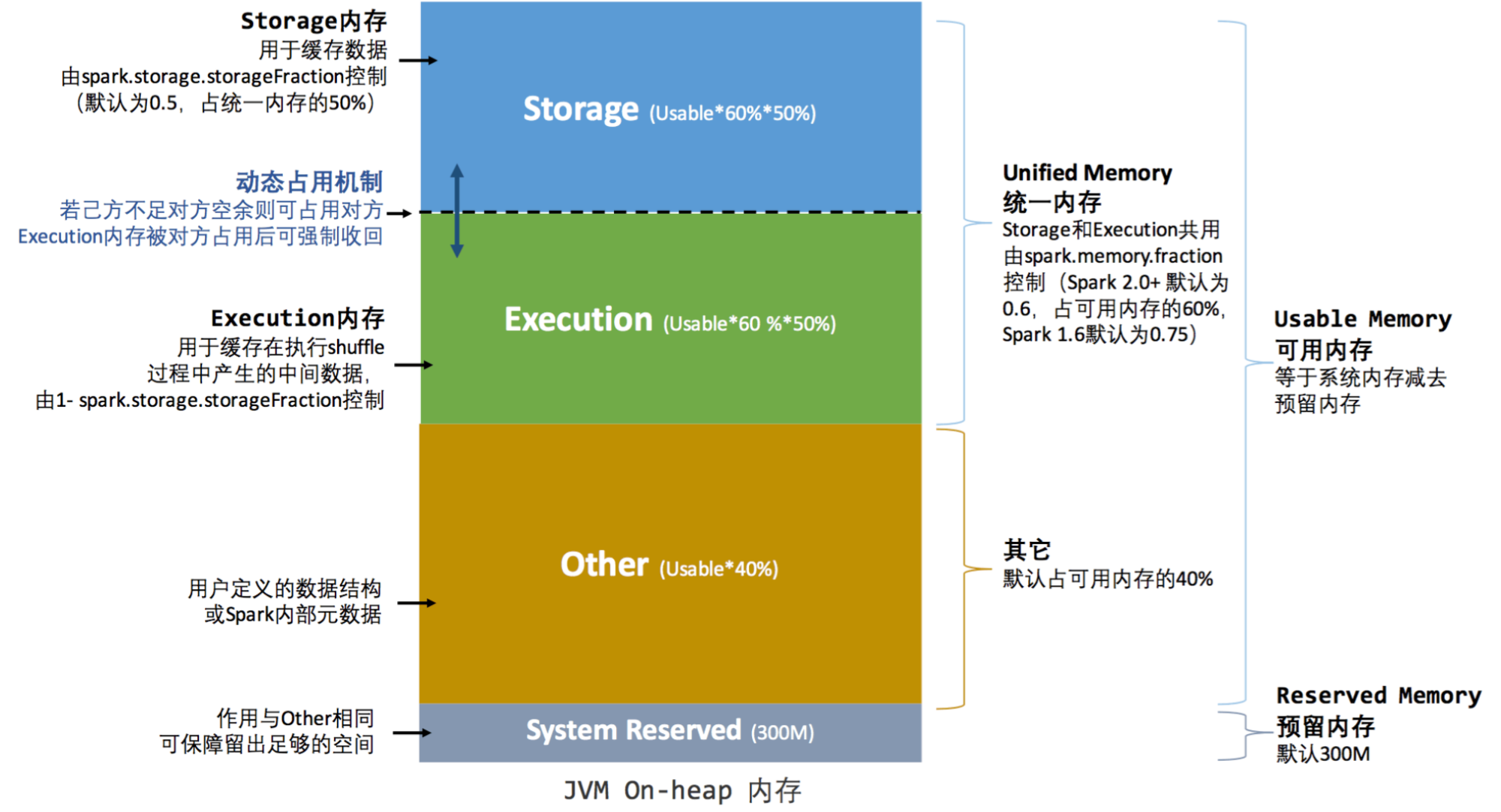
配置参数:
set spark.executor.memory=10G;
spark.memory.fraction:默认0.6,包含storage+execution。
spark.memory.storageFraction:storage的占比,默认0.5。
10G堆内存被划分为4部分。其中最重要的是执行和存储两部分。
-------------------------------------------------------------------
storage(存储内存):用于出处RDD和广播数据。
execution(执行内存):用于shuffle、join、order和聚合中的计算的内存
执行和存储共享一个统一的区域(M),当不使用执行内存时,存储可以获取所有可用内存,反之亦然。如有必要,执行可能会逐出存储,但前提是总存储内存使用量低于某个阈值 (R),由于实现的复杂性,存储可能不会驱逐执行。
-------------------------------------------------------------------
other:默认占堆内存的40%
用户自定义的数据结构,spark元数据。
用户内存用于存储用户代码生成的对象及包括 RDD 的依赖关系、任务的调度信息、分区信息等。
如用户UDF在处理partition中的记录时,其遍历的记录可以存储在Other区,当需要将RDD缓存时,将会序列化或不序列化的方式以Block的形式存储到Storage内存中。
-------------------------------------------------------------------
Reserved Memory:这是为Spark内部使用保留的一部分内存,默认大小为300MB,这部分内存不参与execution和storage内存的分配
堆外内存:
jvm内的堆外内存:使用spark.executor.memoryOverhead配置默认开启,默认值为executor.memory的0.1倍,最低384M。
主要用途:
数据序列化和反序列化:在进行网络传输或写入磁盘时需要对数据进行序列化,在读取或接收时则需要反序列化。
Java NIO Buffer:例如直接缓冲区(Direct Buffer),它们不占用JVM堆内存而是使用本地内存。
PySpark工作进程:如果使用了 PySpark,那么Python进程本身也会占用一部分内存。
其他系统开销:包括但不限于连接器、缓存等。
非堆内存:
jvm外的原生内存:使用spark.memory.offHeap.enable=true和spark.memory.offHeap.size=1g
配置,默认不开启。主要用于执行和存储spark任务(与堆中的execution和storage memory相同功能),解决Java对象开销大和GC的问题。
使用场景
序列化数据存储:将序列化的数据存储在堆外内存中,可以提高数据处理效率。例如,当使用序列化存储级别(如
MEMORY_ONLY_SER或MEMORY_AND_SER)存储 RDD 时,数据可以存储在堆外内存中,以节省空间和提高性能。网络通信:在 Spark 的 Shuffle 过程中,涉及到大量的数据传输,使用堆外内存可以加速数据的传输和接收。Spark 的 Netty 网络通信框架可以使用堆外内存,减少数据复制,提高网络通信效率。
driver内存
spark.driver.memory driver 堆内存,6g
spark.driver.memoryOverhead driver 非堆内存
spark.driver.cores driver cpu核数
spark driver用于保存元数据和一些结果数据。
spark元数据:代码、任务执行信息、数据分区信息等
参考:
https://archive.apache.org/dist/spark/docs/3.3.2/configuration.html
https://spark.apache.org/docs/3.2.1/tuning.html#memory-management-overview
https://zhuanlan.zhihu.com/p/115888408
https://juejin.cn/post/6954242838162833422
https://juejin.cn/s/spark%20%E5%A0%86%E5%A4%96%E5%86%85%E5%AD%98%E4%BD%9C%E7%94%A8
评论