
kafka3.9.1KRaft模式集群部署
Apache Kafka 3.9.1 支持 KRaft(Kafka Raft Metadata)模式,即无需依赖 ZooKeeper 的纯 Kafka 元数据管理方式。以下是 KRaft 模式下部署 Kafka 集群的详细步骤,适用于生产或测试环境。
🧩 前提条件
至少 3 台服务器(用于高可用集群,也可单机模拟多节点)
📁 步骤概览
下载并解压 Kafka
生成集群 ID(Cluster ID)
为每个节点配置
server.properties启动 Kafka 节点
验证集群状态
✅ 详细步骤
1️⃣ 下载并解压 Kafka
官网:wget https://dlcdn.apache.org/kafka/3.9.1/kafka_2.13-3.9.1.tgz
镜像:wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/3.9.1/kafka_2.13-3.9.1.tgz
tar -xzf kafka_2.13-3.9.1.tgz
cd kafka_2.13-3.9.1注意:
2.13是 Scala 版本,与功能无关,可忽略。
2️⃣ 生成唯一的 Cluster ID
KRaft 模式需要一个全局唯一的 Cluster ID,使用 Kafka 自带工具生成:
bin/kafka-storage.sh random-uuid输出示例:
YE6diPFtRfK5er9LMfqmEw记录该 ID,后续所有节点都要使用相同的值。
3️⃣ 配置每个节点的 server.properties
KRaft 模式中,每个 Kafka 节点需指定角色(controller、broker 或两者兼有)。建议在 3 节点集群中让每个节点同时承担 controller + broker 角色(简化部署)。
📌 示例拓扑(3 节点)
节点 ID 必须唯一且固定(不能动态分配)。
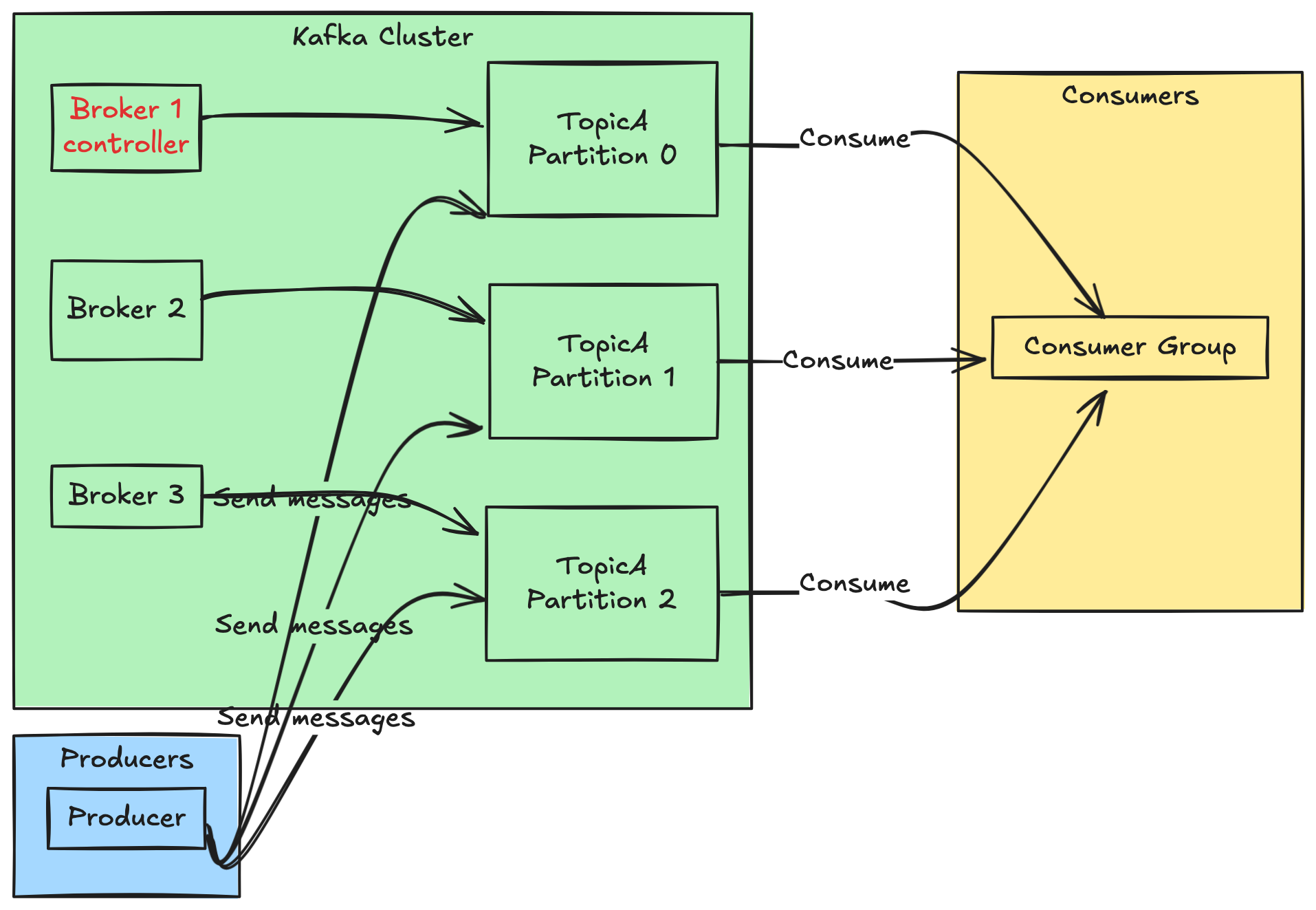
📄 配置文件模板(每个节点略有不同)
以 node1 为例(config/kraft/server.properties):
# 节点唯一 ID(必须与 --meta-data-dir 初始化时一致)
process.roles=broker,controller
node.id=1
# 控制器监听器(用于 controller 间通信)
controller.listener.names=CONTROLLER
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
# 对外 advertised 地址(客户端连接用)
advertised.listeners=PLAINTEXT://192.168.1.211:9092
# 控制器法定人数(quorum)配置,格式:id@host:port
controller.quorum.voters=1@192.168.1.211:9093,2@192.168.1.212:9093,3@192.168.1.213:9093
# 数据和元数据存储目录
log.dirs=/home/phoenix/data/kafka/kafka-logs
metadata.log.dir=/home/phoenix/data/kafka/kafka-metadata
# 其他可选配置
inter.broker.listener.name=PLAINTEXT
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
default.replication.factor=3
num.partitions=3⚠️ 注意:
node.id每个节点不同(1、2、3)
advertised.listeners中 IP 改为当前节点 IP
controller.quorum.voters所有节点必须完全一致
对 node2 和 node3,只需修改:
node.idadvertised.listeners中的 IP
4️⃣ 格式化元数据日志目录(每个节点)
使用第 2 步生成的 Cluster ID,对每个节点执行:
/home/phoenix/apps/kafka_2.13-3.9.1/bin/kafka-storage.sh format -t YE6diPFtRfK5er9LMfqmEw -c config/kraft/server.properties✅ 成功提示:
Formatting metadata directory /tmp/kafka-metadata with cluster id VXu8rBdZQmOvGqW6iNjKlA
❗注意:此操作只能执行一次!重复执行会清空元数据。
5️⃣ 启动 Kafka 节点
在每台机器上运行:
JAVA_HOME=/home/phoenix/apps/jdk-17.0.18+8
/home/phoenix/apps/kafka_2.13-3.9.1/bin/kafka-server-start.sh /home/phoenix/apps/kafka_2.13-3.9.1/config/kraft/server.properties建议使用 nohup 或 systemd 管理后台进程。
6️⃣ 验证集群状态
查看控制器选举状态:
/home/phoenix/apps/kafka_2.13-3.9.1/bin/kafka-metadata-quorum.sh --bootstrap-server 192.168.1.211:9092 describe --status创建测试 Topic:
/home/phoenix/apps/kafka_2.13-3.9.1/bin/kafka-topics.sh --create --topic test --partitions 3 --replication-factor 3 --bootstrap-server 192.168.1.211:9092列出 Topic:
/home/phoenix/apps/kafka_2.13-3.9.1/bin/kafka-topics.sh --list --bootstrap-server 192.168.1.211:9092发送接收消息:
/home/phoenix/apps/kafka_2.13-3.9.1/bin/kafka-console-producer.sh --bootstrap-server 192.168.1.211:9092 --topic test
/home/phoenix/apps/kafka_2.13-3.9.1/bin/kafka-console-consumer.sh --bootstrap-server 192.168.1.212:9092 --topic test --from-beginning🔐 安全建议(生产环境)
使用
SASL_SSL或SSL替代PLAINTEXT分离 controller 和 broker 角色(大型集群)
监控
/tmp目录(建议改用持久化路径如/data/kafka/logs)设置 JVM 参数(堆内存、GC 等)
开机自启动:
sudo vim /etc/systemd/system/kafka.service
=================内容如下===================
[Unit]
Description=Apache Kafka 3.9.1 (KRaft)
After=network.target syslog.target
Requires=network.target
[Service]
Type=simple
# 重要:将以下用户和组修改为运行Kafka的实际用户,如 kafka: kafka
User=phoenix
Group=phoenix
# 设置Kafka所需的环境变量,特别是JAVA_HOME
Environment="JAVA_HOME=/home/phoenix/apps/jdk-17.0.18+8"
# 核心:启动命令。请根据你的实际安装路径和配置文件位置修改。
ExecStart=/home/phoenix/apps/kafka_2.13-3.9.1/bin/kafka-server-start.sh /home/phoenix/apps/kafka_2.13-3.9.1/config/kraft/server.properties
# 停止命令,确保优雅关闭
ExecStop=/home/phoenix/apps/kafka_2.13-3.9.1/bin/kafka-server-stop.sh
# 重启配置
Restart=on-failure
RestartSec=10
# 进程管理
TimeoutStopSec=90
LimitNOFILE=100000
[Install]
WantedBy=multi-user.target
===========================================
# 重新加载 systemd,使新服务文件生效
sudo systemctl daemon-reload
# 设置 Kafka 服务为开机自启
sudo systemctl enable kafka.service
# 立即启动服务(无需重启)
sudo systemctl start kafka.service
# 检查服务状态
sudo systemctl status kafka.service
评论