
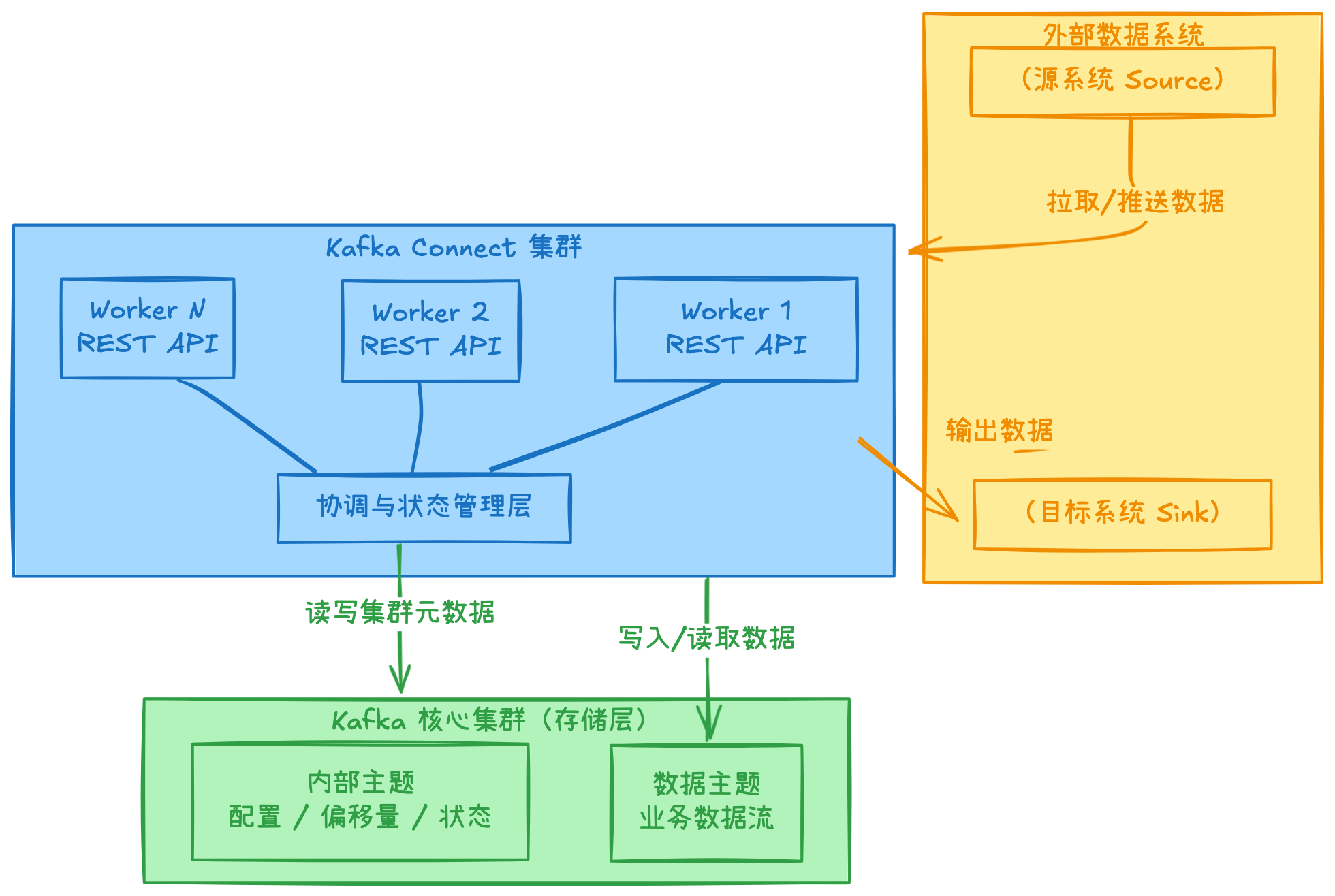
Kafka Connect分布式服务
部署Kafka Connect 3.9的分布式集群,核心是配置一个由多个Worker进程组成的、能够自动协调和容错的系统。与单机模式不同,分布式模式下,集群的状态和配置都存储在Kafka内部主题中,以实现高可用。
下面的表格整理了部署的核心步骤概览:
🔧 详细配置与操作指南
1. 调整Worker配置文件
编辑kafka集群的各个节点:/home/phoenix/apps/kafka_2.13-3.9.1/config/connect-distributed.properties ,以下参数至关重要:
# 连接到你的Kafka集群(替换为你的broker地址)
bootstrap.servers=192.168.1.211:9092,192.168.1.212:9092,192.168.1.213:9092
# 集群的唯一标识,不能与任何消费者组ID冲突[citation:2]
group.id=connect-cluster-1
# 内部主题名称(通常使用默认值,但需提前创建)
config.storage.topic=connect-configs
config.storage.replication.factor=3
offset.storage.topic=connect-offsets
offset.storage.replication.factor=3
status.storage.topic=connect-status
status.storage.replication.factor=3
# 关键:设置键和值的转换器,例如JSON
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
# 允许转换器使用Schemaless模式
key.converter.schemas.enable=false
value.converter.schemas.enable=false
# REST API监听地址,确保可从其他节点访问
# 注:需要修改为当前服务器ip
listeners=HTTP://192.168.1.211:8083
# 设置内部通信密钥(任意字符串,但所有节点必须相同!)
internal.key=your-secret-internal-key-12345
# 修改 plugin.path,直接写根目录,connect会自动扫描子目录
plugin.path=/home/phoenix/apps/kafka_2.13-3.9.1/plugins2. 手动创建内部主题
这是部署成功的关键前置步骤。必须按以下要求创建,否则集群可能无法正常工作,只需创建一次:
# 创建配置存储主题(单分区,Compact策略)
/home/phoenix/apps/kafka_2.13-3.9.1/bin/kafka-topics.sh --create --bootstrap-server 192.168.1.211:9092 \
--topic connect-configs \
--partitions 1 --replication-factor 3 \
--config cleanup.policy=compact
# 创建偏移量存储主题(多分区,Compact策略)
/home/phoenix/apps/kafka_2.13-3.9.1/bin/kafka-topics.sh --create --bootstrap-server 192.168.1.211:9092 \
--topic connect-offsets \
--partitions 25 --replication-factor 3 --config cleanup.policy=compact
# 创建状态存储主题(多分区,Compact策略)
/home/phoenix/apps/kafka_2.13-3.9.1/bin/kafka-topics.sh --create --bootstrap-server 192.168.1.211:9092 \
--topic connect-status \
--partitions 5 --replication-factor 3 \
--config cleanup.policy=compact删除topic:/home/phoenix/apps/kafka_2.13-3.9.1/bin/kafka-topics.sh --delete --topic connect-offsets --bootstrap-server 192.168.1.211:9092
configs、offsets、status三个主题的作用如下:
1. configs 主题
作用:存储连接器的配置信息。
内容包括:
连接器本身的配置(如 name、connector.class、tasks.max 等)
每个任务(task)的配置
用途:
当 Connect Worker 启动或重新平衡(rebalance)时,从该主题读取配置以恢复连接器和任务。
支持分布式模式下多个 Worker 之间共享配置。
特点:
使用 压缩(compacted) 日志策略(cleanup.policy=compact),确保每个连接器/任务只保留最新配置。
2. offsets 主题
作用:记录 Source 连接器中每个任务已处理到的数据源位置(即偏移量)。
内容包括:
源系统中的位置信息(例如数据库的 binlog 位置、文件的字节偏移、Kafka 分区的 offset 等)
通常以 (connector, task, partition) 为键,偏移量为值
用途:
在任务重启或故障转移后,能从上次处理的位置继续,避免重复或丢失数据。
特点:
也使用 压缩(compacted) 策略,只保留每个分区的最新偏移量。
注意:Sink 连接器的 offset 由 Kafka Consumer Group 机制管理(通过 __consumer_offsets 主题),不写入此 offsets 主题。
3. status 主题
作用:记录连接器及其任务的运行状态。
内容包括:
连接器状态(RUNNING、PAUSED、FAILED 等)
每个任务的状态(包括错误信息、worker ID 等)
用途:
提供给 REST API 查询当前连接器/任务状态。
在 Worker 故障或重新分配任务时,帮助新 Worker 了解之前的状态。
特点:
同样使用 压缩(compacted) 策略,保留最新状态。
3. 启动与验证集群
启动:将配置好的connect-distributed.properties文件分发到所有计划运行Worker的服务器上,然后在每台服务器上执行:
/home/phoenix/apps/kafka_2.13-3.9.1/bin/connect-distributed.sh /home/phoenix/apps/kafka_2.13-3.9.1/config/connect-distributed.properties验证:启动后,访问任意Worker的REST API检查集群状态:
# 查看connect基本信息
http://192.168.1.211:8083/
列出 connectors:
http://192.168.1.211:8083/connectors你应该能看到Kafka Connect版本等基本信息。
🚀 高级配置与运维建议
生产环境考量
高可用:至少部署3个Worker节点,并分布在不同的物理机或可用区。
性能调优:根据数据量调整
tasks.max参数以实现并行处理;对于跨国或高延迟网络,可适当调大producer.max.request.size和consumer.max.poll.records。安全:务必配置SSL/TLS加密、设置
rest.extension.classes开启REST API认证,并严格管理防火墙规则。
连接器插件管理
将自定义或第三方连接器插件(JAR包)放入每台Worker服务器的
plugin.path目录下(需在配置文件中指定),然后重启Worker即可。
常见问题排查
Worker无法加入集群:检查
group.id是否唯一;确认所有Worker的bootstrap.servers配置正确且网络连通。任务不均衡:检查
status.storage.topic的分区数,足够的分区数是任务在Worker间均衡分布的前提。REST API无法访问:确认
rest.host.name和防火墙设置允许外部访问。
开机自启动
sudo vim /etc/systemd/system/kafkaconnect.service
=================内容如下===================
[Unit]
Description=Apache Kafka connect
After=kafka.service
Requires=network.target
[Service]
Type=simple
# 重要:将以下用户和组修改为运行Kafka的实际用户,如 kafka: kafka
User=phoenix
Group=phoenix
# 设置Kafka所需的环境变量,特别是JAVA_HOME
Environment="JAVA_HOME=/home/phoenix/apps/jdk-17.0.18+8"
# 核心:启动命令。请根据你的实际安装路径和配置文件位置修改。
ExecStart=/home/phoenix/apps/kafka_2.13-3.9.1/bin/connect-distributed.sh /home/phoenix/apps/kafka_2.13-3.9.1/config/connect-distributed.properties
# 重启配置
Restart=on-failure
RestartSec=10
# 进程管理
TimeoutStopSec=90
LimitNOFILE=100000
[Install]
WantedBy=multi-user.target
===========================================
# 重新加载 systemd,使新服务文件生效
sudo systemctl daemon-reload
# 设置 Kafka 服务为开机自启
sudo systemctl enable kafkaconnect.service
# 立即启动服务(无需重启)
sudo systemctl start kafkaconnect.service
# 检查服务状态
sudo systemctl status kafkaconnect.service💎 核心总结
部署Kafka Connect分布式集群的关键在于:正确配置并统一所有Worker节点的group.id、提前按要求手动创建三个内部存储主题、并通过REST API(而非配置文件)来管理连接器。
评论