
这是一个flink读取kafka数据写入paimon的java api例子。
paimon表使用hive metastore管理,写入后可以基于hive进行统计分析。
执行流程如下:
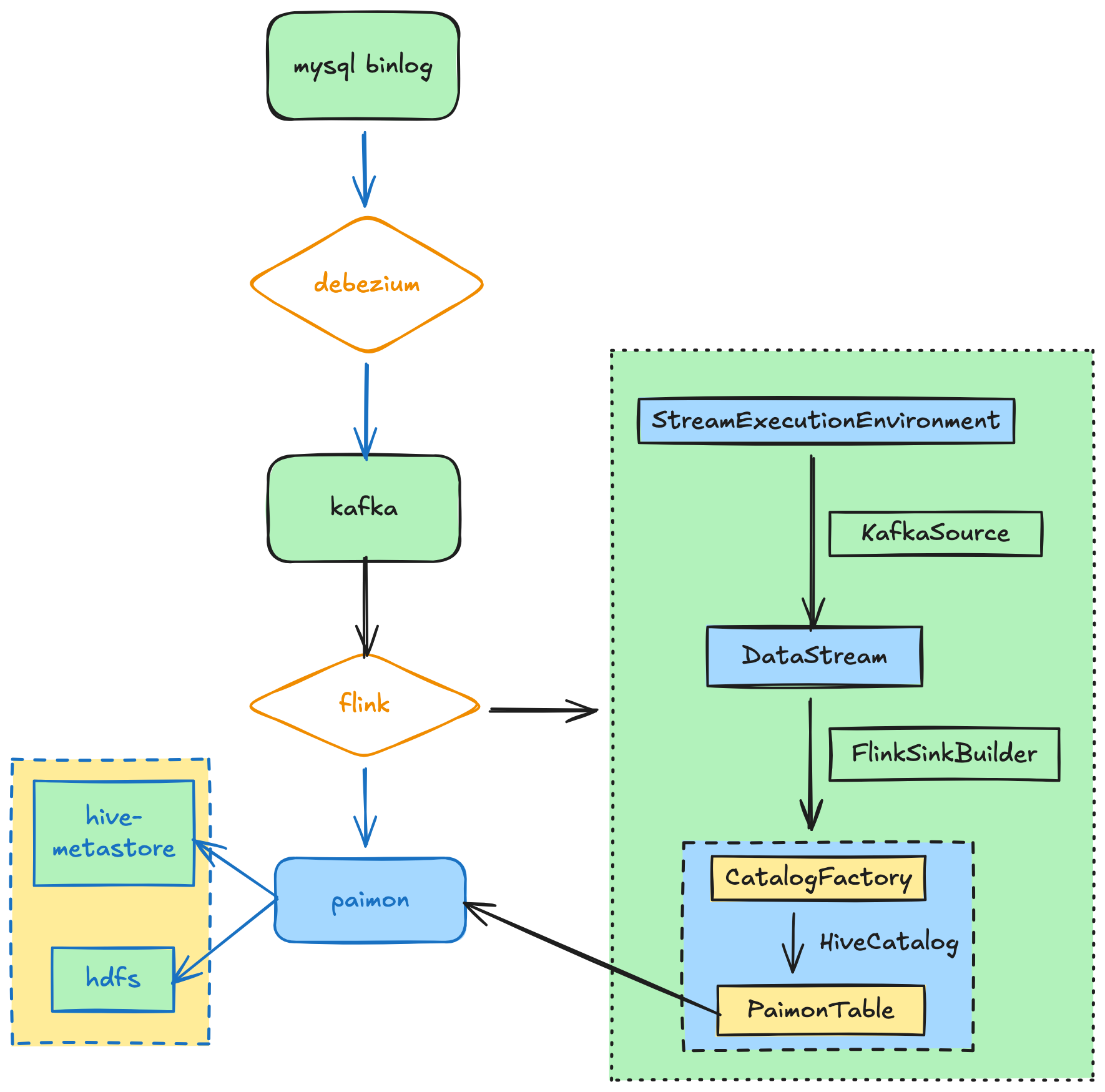
采集kafka多个topic数据到paimon表中,paimon元数据写入hive,后续可以在hive中查看paimon表。
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.configuration.CheckpointingOptions;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.configuration.RestOptions;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.types.DataType;
import org.apache.flink.types.Row;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.panda.bigdata.utils.DateTimeHelper;
import com.panda.bigdata.utils.MultiConfigHelper;
import com.panda.bigdata.utils.SafeStringSchema;
import com.panda.bigdata.utils.TimestampValidator;
import org.apache.paimon.catalog.Catalog;
import org.apache.paimon.catalog.CatalogContext;
import org.apache.paimon.catalog.CatalogFactory;
import org.apache.paimon.catalog.Identifier;
import org.apache.paimon.flink.sink.FlinkSinkBuilder;
import org.apache.paimon.options.Options;
import org.apache.paimon.schema.Schema;
import org.apache.paimon.table.Table;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.regex.Pattern;
/**
* 采集kafka多个topic数据到paimon表中,paimon元数据写入hive,后续可以在hive中查看paimon表
*
* 提交命令:
*/
public class FlinkKafka2PaimonMultiOutStream {
// 定义 Side Output Tags
private static final OutputTag<String> stream_paimon_tag = new OutputTag<>("stream-paimon"){};
// private static final OutputTag<String> stream_doris_tag = new OutputTag<>("stream-doris"){};
// 主流
// private static final String stream_main_tag = "stream-other";
public static void main(String[] args) throws Exception {
final Logger log = LoggerFactory.getLogger(FlinkKafka2PaimonMultiOutStream.class);
String configPath = args.length > 0 ? args[0] : "/home/phoenix/git/my_bigdata/src/main/resources/config/kafka2paimon_withhivecatalog.conf";
String kafka_bootstrap_servers = MultiConfigHelper.getProperty(configPath, "kafka_bootstrap_servers");
String kafk_topic_pattern = MultiConfigHelper.getProperty(configPath, "kafka_topic_pattern");
String kafka_group_id = MultiConfigHelper.getProperty(configPath, "kafka_group_id");
String kafka_offsets_initializer = MultiConfigHelper.getProperty(configPath, "kafka_offsets_initializer");
// String hive_catalog_name = MultiConfigHelper.getProperty(configPath, "hive_catalog_name");
String hive_metastore_uri = MultiConfigHelper.getProperty(configPath, "hive_metastore_uri");
String paimon_default_db = MultiConfigHelper.getProperty(configPath, "paimon_default_db");
String paimon_warehouse_path = MultiConfigHelper.getProperty(configPath, "paimon_warehouse_path");
String paimon_ods_table_name = MultiConfigHelper.getProperty(configPath, "paimon_ods_table_name");
String paimon_ods_db_name = MultiConfigHelper.getProperty(configPath, "paimon_ods_db_name");
String flink_checkpoint_path = MultiConfigHelper.getProperty(configPath, "flink_checkpoint_path");
log.info("配置文件:{}", configPath);
log.info("配置信息:{}, {}, {}, {}", kafka_bootstrap_servers, kafk_topic_pattern, kafka_group_id, kafka_offsets_initializer);
Configuration flinkConf = new Configuration();
flinkConf.set(RestOptions.BIND_PORT, "8189"); // Rest端口
flinkConf.set(CheckpointingOptions.CHECKPOINT_STORAGE, "filesystem");
flinkConf.set(CheckpointingOptions.CHECKPOINTS_DIRECTORY, flink_checkpoint_path);
flinkConf.setString("pipeline.object-reuse", "true"); // 启用对象复用
flinkConf.setString("serialization.force-kryo", "false"); // 不强制所有类型用Kryo
flinkConf.setString("serialization.kryo.registrator", "org.apache.flink.api.java.typeutils.runtime.kryo.FlinkKryoRegistrar");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(flinkConf);
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 10000));
env.enableCheckpointing(60000); // 建议开启检查点以保证 Exactly-Once
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(5000);
// 关键:作业取消后保留Checkpoint(否则无法用于恢复)
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 1. 配置并创建 Kafka Source
OffsetsInitializer offsetsInitializer = OffsetsInitializer.earliest();
if (kafka_offsets_initializer.equals("latest")){
offsetsInitializer = OffsetsInitializer.latest();
}
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers(kafka_bootstrap_servers)
.setTopicPattern(Pattern.compile(kafk_topic_pattern))
.setStartingOffsets(offsetsInitializer) // 从最早偏移量开始(可改为latest)
.setGroupId(kafka_group_id)
.setValueOnlyDeserializer(new SafeStringSchema()) // 读取原始JSON字符串
.build();
DataStream<String> rawKafkaStream = env.fromSource(
kafkaSource,
WatermarkStrategy.noWatermarks(),
"flink_kafka2paimon_stream_" + kafk_topic_pattern.replace(".*", "")
);
// 2. 解析 JSON 并进行分流
SingleOutputStreamOperator<String> mainStream = rawKafkaStream
.process(new ProcessFunction<String, String>() {
private static final long serialVersionUID = 1L;
// private final ObjectMapper objectMapper = new ObjectMapper();
@Override
public void processElement(String value, ProcessFunction<String, String>.Context ctx, Collector<String> out) throws Exception {
// JsonNode jsonNode = objectMapper.readTree(value);
// String type = jsonNode.get("type").asText();
// 发送到主流
// out.collect(value);
//发送到paimon
ctx.output(stream_paimon_tag, value);
//发送到doris
// ctx.output(stream_doris_tag, value);
}
});
// --- DataStream API 写入 Paimon ---
// 准备 Paimon Catalog 配置
Options catalogOptions = new Options();
catalogOptions.set("type", "paimon");
catalogOptions.set("metastore", "hive");
catalogOptions.set("uri", hive_metastore_uri);
catalogOptions.set("default-database", paimon_default_db);
catalogOptions.set("warehouse", paimon_warehouse_path);
// hadoop-conf-dir 和 fs.defaultFS 可以通过 flink-conf.yaml 或环境变量设置,这里省略
CatalogContext catalogContext = CatalogContext.create(catalogOptions);
Catalog paimonCatalog = CatalogFactory.createCatalog(catalogContext);
// 获取 Paimon 表实例
Table paimonTable = getPaimonTable(paimonCatalog, paimon_ods_db_name, paimon_ods_table_name);
// Table dorisTable = null;
// Table tableOther = null;
// 将分流后的数据写入对应的 Paimon 表
DataStream<Row> paimonStream = mainStream.getSideOutput(stream_paimon_tag)
.map(jsonStr -> getPaimonRowData(jsonStr))
;
DataType rowDataType = DataTypes.ROW(
DataTypes.FIELD("db_name", DataTypes.STRING()),
DataTypes.FIELD("table_name", DataTypes.STRING()),
DataTypes.FIELD("dt", DataTypes.STRING()),
DataTypes.FIELD("create_time", DataTypes.STRING()),
DataTypes.FIELD("raw_msg", DataTypes.STRING())
);
FlinkSinkBuilder flinkBuilder = new FlinkSinkBuilder(paimonTable)
.forRow(paimonStream, rowDataType)
;
flinkBuilder.build();
env.execute("Flink Kafka 2 Paimon MultiStream Job (DataStream API)");
}
// 组装paimon行数据
public static Row getPaimonRowData(String jsonStr) {
String db_name = "";
String table_name = "";
String dt = DateTimeHelper.getCurrentTimestampFormatted(DateTimeHelper.DATE_MONTH_FORMATTER);
String create_time = DateTimeHelper.getCurrentTimestampFormatted(DateTimeHelper.STANDARD_FORMATTER);
try {
ObjectMapper mapper = new ObjectMapper();
JsonNode rootNode = mapper.readTree(jsonStr);
JsonNode createTimeNode = rootNode.path("payload").path("after").path("create_time");
if (!createTimeNode.isMissingNode() && !createTimeNode.isNull()) {
// createTimeStr发现两种格式:1756940435000(13位时间戳) 和 2025-08-30T04:39:46Z(utc时间字符串),分别处理
String createTimeStr = createTimeNode.asText();
if (createTimeStr.contains("T") && createTimeStr.contains("z")) {
dt = DateTimeHelper.convertIsoToFormatted(createTimeStr, DateTimeHelper.DATE_MONTH_FORMATTER);
} else if(TimestampValidator.isValidTimestamp(createTimeStr)){
dt = DateTimeHelper.convertTimestampToCustomFormat(createTimeStr, DateTimeHelper.DATE_MONTH_FORMATTER);
}
}
db_name = rootNode.path("payload").path("source").path("db").asText();
table_name = rootNode.path("payload").path("source").path("table").asText();
if(db_name == null || db_name == ""){
db_name = "other";
}
if(table_name == null || table_name == ""){
table_name = "other";
}
} catch(Exception e){
System.out.println(e);
}
return Row.of(db_name, table_name, dt, create_time, jsonStr);
}
// 获取Paimon表
private static Table getPaimonTable(Catalog catalog, String database, String tableName) {
Identifier identifier = Identifier.create(database, tableName);
Table table = null;
try {
List<String> tableList = catalog.listTables(database);
if (!tableList.contains(tableName)) {
System.out.println("Creating paimon table: " + tableName);
// 2.5 创建表
Map<String, String> tableOptions = new HashMap<>();
tableOptions.put("file.format", "parquet"); // 文件格式:parquet
// 分区提交策略
tableOptions.put("sink.partition-commit.policy.kind", "metastore,success-file");
// 启用Hive Metastore分区表
tableOptions.put("metastore.partitioned-table", "true");
tableOptions.put("metastore.partitioned-table", "true");
tableOptions.put("hive.input.recursive.dir", "true");
tableOptions.put("hive.input.dir.recursion.level", "1");
Schema schema = Schema.newBuilder()
.column("db_name", org.apache.paimon.types.DataTypes.STRING()) // 数据库名(分区字段)
.column("table_name", org.apache.paimon.types.DataTypes.STRING()) // 表名(分区字段)
.column("dt", org.apache.paimon.types.DataTypes.STRING()) // 日期分区(如yyyyMM,分区字段)
.column("create_time", org.apache.paimon.types.DataTypes.STRING())
.column("raw_msg", org.apache.paimon.types.DataTypes.STRING())
.partitionKeys("db_name", "table_name", "dt")
.options(tableOptions)
.build();
catalog.createTable(identifier, schema, true);
}
table = catalog.getTable(identifier);
} catch (Exception e) {
throw new RuntimeException("创建paimon表失败: " + tableName, e);
}
return table;
}
}
评论