
dolphin提交flink job
🧩 前提条件
已安装并启动 Apache DolphinScheduler(建议 v3.0+)
已安装 Apache Flink(Standalone 或 YARN 模式均可)
DolphinScheduler 的 Worker 节点可以访问 Flink 安装目录或能通过命令行执行
flink命令若使用 YARN 模式,确保 Hadoop 和 YARN 环境已配置好
第一步:在 DolphinScheduler 中配置 Flink 环境
配置 Flink_HOME
如果部署的standalone服务,在standalone-server/conf/dolphinscheduler_env.sh中添加flink配置:
export FLINK_HOME=/home/phoenix/apps/flink-1.20.3
export HADOOP_HOME=/home/phoenix/apps/hadoop-2.10.2
export HADOOP_CONF_HOME=/home/phoenix/apps/hadoop-2.10.2/etc/hadoop
PATH=$PATH:$FLINK_HOME/bin:$HADOOP_HOME/bin配置好以后重启dolphin服务。
第二步:在 DolphinScheduler Web UI 中创建 Flink 任务
方法1:创建工作流并添加 Flink 任务节点
进入项目 → 工作流定义 → 创建工作流
拖拽左侧 “Flink” 节点到画布中
双击该节点进行配置
配置 Flink 任务参数:
⚠️ 注意:
Main Jar Package必须是 资源中心 中已上传的 JAR 文件(见下一步)。
上传 Flink JAR 到资源中心:
在顶部菜单点击 资源中心 → 文件管理
点击 上传,选择你的 Flink 作业 JAR 包(如
my-flink-job.jar)上传后,路径会显示为:
my-flink-job.jar(根目录)或/dir/my-flink-job.jar
在 Flink 任务节点的 Main Jar Package 字段中填写该路径(不含前导
/)
问题:
提交flink任务后,dolphin显示任务完成,但是flink实时任务会长期执行,dolphin结束则flink client结束,flink job会因为没有flink client心跳而取消整个作业。
方法2:通过shell脚本提交flink job
提交flink job后,定期检测yarn application的状态,dolphin任务一直执行,便于在flink作业失败后及时报警。
1)创建一个任务用于提交flink job
$FLINK_HOME/bin/flink run-application -d \
-t yarn-application \
-D yarn.application.name="flink_kafka2paimon_prod_v2" \
-s hdfs:///user/flink/checkpoint/FlinkKafka2PaimonMultiOutStream/12c7c434f12e415feaf1b9205c7d974f/chk-1831 \
-D containerized.master.env.JAVA_HOME=/home/phoenix/apps/jdk-19.0.2 \
-D containerized.taskmanager.env.JAVA_HOME=/home/phoenix/apps/jdk-19.0.2 \
-D containerized.jobmanager.env.JAVA_HOME=/home/phoenix/apps/jdk-19.0.2 \
-D jobmanager.memory.process.size=2048m \
-D taskmanager.memory.process.size=2048m \
-D taskmanager.numberOfTaskSlots=1 \
-D parallelism.default=1 \
-D yarn.application.queue=root.phoenix \
-D yarn.log-aggregation.enable=true \
-c com.panda.bigdata.kafka2paimon.FlinkKafka2PaimonMultiOutStream \
flink/my_bigdata-1.0-SNAPSHOT.jar2)在dolphin的资源中心中创建shell脚本:
#!/bin/bash
set -e
yarn_app_name="$1"
# === 提取 application_id ===
APP_ID=$(yarn application -list 2>/dev/null | grep "$yarn_app_name" | awk '{print $1}')
if [ -z "$APP_ID" ]; then
echo "[ERROR] Failed to extract YARN application ID from output."
echo "Please ensure the Flink command outputs an application ID (e.g., in yarn-application mode)."
exit 1
fi
echo "[INFO] Detected YARN Application ID: $APP_ID"
# === 监控 YARN 应用状态 ===
SLEEP_INTERVAL=300 # 每300秒检查一次
# MAX_CHECKS=$(( MAX_WAIT_MINUTES * 60 / SLEEP_INTERVAL ))
CHECK_COUNT=0
while [ true ]; do
sleep $SLEEP_INTERVAL
CHECK_COUNT=$((CHECK_COUNT + 1))
# 获取应用状态(使用 yarn application -status)
STATUS_OUTPUT=$(yarn application -status "$APP_ID" 2>/dev/null || true)
STATE_LINE=$(echo "$STATUS_OUTPUT" | grep -i "State :" || echo "")
FINAL_STATE_LINE=$(echo "$STATUS_OUTPUT" | grep -i "Final-State :" || echo "")
# 优先看 Final-State(作业结束后才有),否则看 State
if [[ -n "$FINAL_STATE_LINE" ]]; then
STATE=$(echo "$FINAL_STATE_LINE" | awk -F: '{print $2}' | tr -d '[:space:]')
elif [[ -n "$STATE_LINE" ]]; then
STATE=$(echo "$STATE_LINE" | awk -F: '{print $2}' | tr -d '[:space:]')
else
# 无法获取状态,可能应用已不存在
echo "[WARN] Cannot retrieve status for $APP_ID. It may have been removed from YARN."
echo "[INFO] Checking if app exists via 'yarn application -list'..."
if yarn application -list 2>/dev/null | grep -q "$APP_ID"; then
echo "[INFO] App still exists but status unknown. Continue monitoring..."
continue
else
echo "[ERROR] Application $APP_ID not found in YARN. Assuming it failed or was killed."
exit 1
fi
fi
echo "[INFO] Current state of $APP_ID: $STATE (check $CHECK_COUNT)"
case "$STATE" in
"FINISHED")
echo "[SUCCESS] Application $APP_ID finished successfully."
exit 0
;;
"FAILED"|"KILLED"|"LOST")
echo "[ERROR] Application $APP_ID ended with state: $STATE"
exit 1
;;
"ACCEPTED"|"RUNNING"|"SUBMITTED")
# 正常运行中,继续监控
continue
;;
*)
echo "[WARN] Unknown state: $STATE. Continue monitoring..."
continue
;;
esac
done
# 超时
echo "[ERROR] Timeout after $MAX_WAIT_MINUTES minutes. Application $APP_ID did not finish."
exit 13) 在dolphin中配置yarn application检测任务:
flink/submit_flink_job.sh "flink_kafka2paimon_prod_v2"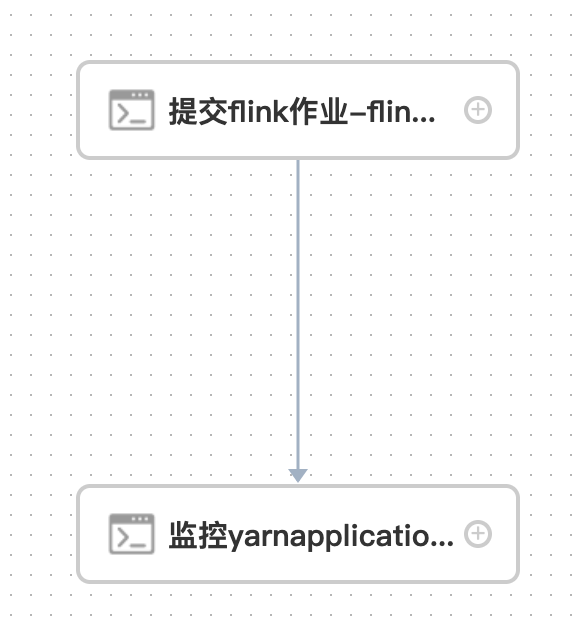
评论