
Flink时间与水印全解析:彻底搞定乱序数据流
在实时计算领域,Flink凭借精准高效的时间处理能力和强悍的乱序数据容错能力,成为主流的流处理引擎。而时间语义(Time)和水印(Watermark),正是Flink区别于其他流处理框架的核心精髓,也是新手入门Flink最容易困惑的知识点。
很多同学刚接触Flink时,总会遇到这些问题:为什么窗口计算迟迟不触发?乱序数据来了为什么会丢失?迟到数据该怎么处理?这些问题的根源,几乎都和时间语义、水印机制理解不到位有关。
本篇博文将从零开始,用通俗的语言、循序渐进的逻辑,带你完整掌握Flink时间与水印的核心知识,从基础概念、三大时间语义,到水印的原理、生成方式、实战配置,再到迟到数据处理和常见踩坑点。
要讲什么?
为什么Flink需要时间语义和水印?—— 实时流的核心痛点
Flink三大时间语义:事件时间、处理时间、摄入时间,该怎么选?
水印(Watermark)核心原理:到底什么是水印?它的作用是什么?
水印的核心特性与生成逻辑
Flink内置水印生成策略:单调递增、固定延迟、自定义水印
迟到数据处理:侧输出流、允许延迟、窗口重新触发
实战案例:基于事件时间和水印的窗口计算
水印使用常见踩坑与优化技巧
总结
一、为什么Flink需要时间语义和水印?—— 实时流的核心痛点
在离线计算中,数据是完整的、静态的,我们可以按照数据本身的时间轻松做分组统计;但实时数据流是无限、无序、乱序的,这是流处理最本质的特征,也是所有问题的源头。
1.1 实时流的两大核心问题
乱序数据:数据产生的顺序和到达Flink的顺序不一致。比如用户在APP上触发点击事件,事件1先发生,事件2后发生,但因为网络抖动、消息队列堆积、设备传输延迟,事件2反而先到达Flink,这就是乱序。
数据延迟:部分数据会滞后很久才到达,可能延迟几秒、几分钟甚至更久,这类数据就是迟到数据。如果直接丢弃,会导致计算结果不准确;如果一直等待,又会影响实时性。
1.2 传统时间处理的缺陷
如果只用数据到达Flink的时间(处理时间)做计算,看似简单,但会出现计算结果和业务实际时间不匹配的问题。比如统计凌晨0点-1点的订单交易额,用处理时间计算时,延迟到1点01分才到达的凌晨订单,会被算到1点-2点的窗口里,结果完全失真。
为了兼顾实时性和结果准确性,Flink引入了独立的时间语义,同时通过水印机制,定义“什么时候不再等待迟到数据”,完美解决乱序和延迟问题。
二、Flink三大时间语义:事件时间、处理时间、摄入时间,该怎么选?
Flink定义了三种时间语义,对应流处理中不同的时间参考标准,我们可以根据业务场景灵活选择,这是使用水印的前提。
2.1 事件时间(Event Time)
定义:数据在业务端实际产生的时间,比如用户点击按钮的时间、传感器采集数据的时间、订单创建的时间,这个时间会随着数据一起传输到Flink。
核心特点:最贴近业务逻辑,计算结果精准,不受网络、集群延迟影响,是生产环境首选的时间语义。
依赖条件:必须从数据中提取事件时间戳,并且配合水印使用,才能处理乱序和迟到数据。
2.2 处理时间(Processing Time)
定义:Flink算子实际处理这条数据的系统时间,由Flink所在机器的系统时钟决定。
核心特点:性能最好,无需额外提取时间戳和生成水印,延迟最低,但不保证结果准确性,受数据传输、集群负载影响极大。
适用场景:对实时性要求极高、允许轻微误差、无乱序数据的简单统计场景,比如实时监控QPS、简单的实时计数。
2.3 摄入时间(Ingestion Time)
定义:数据进入Flink Source算子的时间,介于事件时间和处理时间之间,由Source算子自动生成时间戳,无需手动提取。
核心特点:比处理时间精准一点,比事件时间简单,但同样无法解决业务端产生的乱序问题,实际生产中用得极少,可以理解为过渡性时间语义。
2.4 时间语义选择总结
生产环境优先选事件时间,只要业务数据包含时间戳,一律用事件时间+水印的组合;追求极致实时性、不关注准确性,用处理时间;摄入时间几乎不用。
在Flink中设置时间语义的代码也很简单,核心调用setStreamTimeCharacteristic方法(Flink 1.12版本后,事件时间成为默认语义,无需手动设置)。
三、水印核心原理:到底什么是水印?
理解水印,先抛开复杂的源码,用一个通俗的比喻:水印就是流处理中的“时间进度条”,也是一个“迟到数据的截止通知”。
3.1 水印的本质
水印是Flink数据流中一种特殊的事件标记,本质是一个时间戳,它会告诉下游算子:所有小于当前水印时间戳的数据,都已经全部到达了,之后再出现时间戳小于水印的,就是迟到数据。
举个例子:生成一个时间戳为10:00:00的水印,代表Flink认为,10:00:00之前的所有数据都已经到齐,后续再收到9:59:59的数据,就属于迟到数据。
水印在flink中会定期生成,默认200 ms,时间间隔可以自定义。水印对应时间戳之前的所有窗口都会被触发,不管有没有数据。所以如果出现一条记录的event time是未来的时间,不处理就会导致watermark变为未来时间戳,从而触发所有还没有到达的窗口,正常数据就会被认为是延迟数据,而无法被正常计算。
3.2 水印的核心作用
触发窗口计算:基于事件时间的窗口,不会因为时间到了就自动触发,而是等待水印到达窗口结束时间,才会执行计算。比如10:00-10:10的窗口,只有当水印到达10:10时,窗口才会关闭并计算。
处理延迟数据:通过设置水印延迟时间,给延迟、乱序数据留出缓冲时间,避免统计数据失真。
📌 假设我们要统计 10:00 ~ 10:05 这个窗口内的用户点击次数。
一条数据实际在 10:03 产生,但因为网络抖动,直到 10:06 才到达 Flink;
如果没有水印延迟,窗口在 10:05 就直接关闭,这条 10:03 的数据会被当成过期数据丢掉;
设置 5 秒水印延迟 后,Flink 会等到 10:05 + 5 秒 = 10:10 才真正关闭窗口,这条迟到的数据就能正常参与计算,不会丢失。
3.3 关键误区澄清
水印不是时间,而是一个时间戳标记,和处理时间无关,只和数据的事件时间有关;
水印是单调递增的,不会出现时间倒退的情况(除非手动生成错误水印)。
四、水印的核心特性与生成逻辑
4.1 水印的核心特性
单调递增性:水印只能越来越大,不能倒退,倒退的水印会被下游算子忽略,保证时间进度不会回退。
全局性:水印在整个数据流中传播,从Source算子生成,依次传递到Map、KeyBy、Window等下游算子。
多并行度对齐性:多并行度场景下,下游算子不会单独依据某一个上游分区的水印更新进度,必须等待所有上游分区水印同步后,再推进自身水印,这也是多并行度水印的核心规则。
Flink默认是多并行度运行的,Source算子、窗口算子都会有多个并行子任务,这个时候水印的传播逻辑会变复杂,核心是水印对齐。
>多并行度水印规则
下游算子会接收多个上游并行子任务的水印,下游算子的水印,取所有上游分区水印中最小的那个。
举个例子:KeyBy后有3个上游分区,水印分别是10:00:00、10:00:05、10:00:10,那么下游窗口算子的水印只能是最小的10:00:00,直到最慢的分区水印跟上,整体水印才会推进。
>常见问题:水印不推进
生产中最常见的问题就是窗口不触发,根源就是某个上游分区水印卡住了,比如某个分区长时间没有数据,水印一直停留在旧时间,导致下游水印无法推进。解决办法是设置空闲数据源超时(withIdleness),标记空闲分区,跳过对齐。

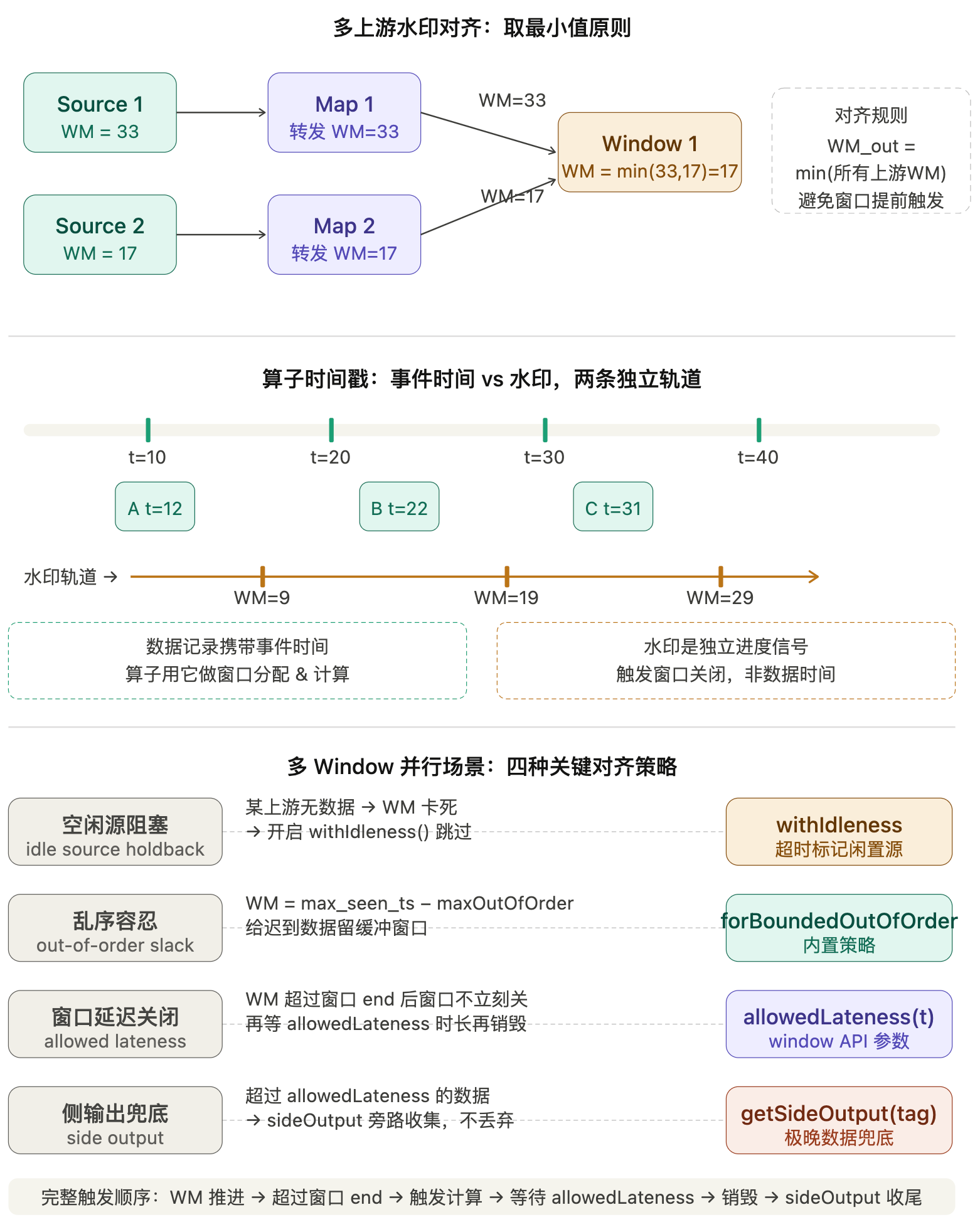
4.2 水印的基础生成逻辑
水印的生成核心公式:
水印时间戳 = 当前数据流中最大的事件时间戳 - 允许的延迟时间
简单来说,就是先找到当前已经到达的所有数据中,事件时间最大的那个值,然后减去我们预设的延迟容忍时间,得到的结果就是新的水印。
示例:当前最大事件时间是10:00:10,设置允许延迟10秒,那么生成的水印时间就是10:00:00,代表10:00:00之前的数据到齐。
五、Flink内置水印生成策略
Flink 1.11版本后,简化了水印生成逻辑,提供了两种开箱即用的内置生成策略,无需手动实现复杂接口,新手也能快速上手。
5.1 单调递增水印(Ascending Timestamps)
适用场景:数据完全有序、无乱序的场景,比如数据源是严格按照事件时间顺序产生的。
逻辑:水印时间戳 = 当前最大事件时间戳,无延迟,直接认为最大事件时间之前的数据全部到齐。
代码示例:
WatermarkStrategy.<Tuple2<String, Long>>forMonotonousTimestamps()
.withTimestampAssigner((event, timestamp) -> event.f1);5.2 固定延迟水印(Bounded Out-of-Orderness)
适用场景:数据存在固定范围的乱序,是生产环境最常用的策略。
逻辑:预设一个固定的延迟时间(比如5秒、10秒),水印时间 = 最大事件时间 - 固定延迟,给乱序数据留出固定的缓冲时间。
代码示例:
// 设置允许10秒的乱序延迟
WatermarkStrategy.<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(10))
.withTimestampAssigner((event, timestamp) -> event.f1);5.3 自定义水印生成器
如果业务场景复杂,乱序延迟不固定(比如高峰期延迟30秒,低峰期延迟5秒),可以实现WatermarkGenerator接口,自定义水印生成逻辑,比如基于周期生成、基于数据条数生成,灵活适配特殊场景。
示例:https://www.pandadt.tech/arc/11LGa483
六、迟到数据处理:三层保障机制
即使设置了水印延迟,还是会有极端延迟的数据到达,Flink提供了三层保障机制,避免数据丢失,保证结果精准。
6.1 第一层:允许窗口延迟(Allowed Lateness)
在窗口配置中,设置允许的额外延迟时间,窗口不会在水印到达后立刻关闭,而是再等待一段时间,这段时间内的迟到数据,会正常参与窗口计算。
6.2 第二层:窗口重新触发(Allowed Lateness + 增量计算)
开启允许延迟后,每来一条迟到数据,窗口会重新触发计算,更新之前的计算结果,保证结果最终准确。
6.3 第三层:侧输出流(Side Output)
超过允许延迟时间的迟到数据,会被丢弃,但我们可以把这类数据输出到侧输出流,后续单独处理、补算数据,这是生产中最常用的兜底方案。
三层机制结合使用,既能保证实时性,又能最大程度避免数据丢失,实现精准的流处理。
七、实战案例:基于事件时间和水印的窗口计算
这里给出完整的Flink代码示例,基于事件时间、固定延迟水印、滚动窗口,处理乱序用户点击数据,包含侧输出流兜底,直接可运行测试。
// 核心代码片段
public class EventTimeWatermarkDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Flink 1.12+ 默认事件时间,无需手动设置
// 1. 读取数据源(模拟乱序点击流)
DataStream<ClickEvent> source = env.socketTextStream("localhost", 9999)
.map(line -> {
String[] arr = line.split(",");
return new ClickEvent(arr[0], Long.parseLong(arr[1]));
});
// 2. 设置水印策略:10秒固定延迟
DataStream<ClickEvent> watermarkStream = source.assignTimestampsAndWatermarks(
WatermarkStrategy.<ClickEvent>forBoundedOutOfOrderness(Duration.ofSeconds(10))
// 配置空闲任务数据流超时(30秒无数据则标记为空闲)
.withIdleness(Duration.ofSeconds(30))
.withTimestampAssigner((event, timestamp) -> event.getEventTime())
);
// 3. 定义侧输出流标签
OutputTag<ClickEvent> lateTag = new OutputTag<ClickEvent>("late-data"){};
// 4. 分组+滚动窗口+允许延迟+侧输出流
DataStream<String> result = watermarkStream
.keyBy(ClickEvent::getUserId)
.window(TumblingEventTimeWindows.of(Duration.ofMinutes(1)))
.allowedLateness(Duration.ofSeconds(5)) // 额外允许5秒延迟
.sideOutputLateData(lateTag) // 迟到数据打入侧输出流
.process(new ProcessWindowFunction<ClickEvent, String, String, TimeWindow>() {
@Override
public void process(String s, Context context, Iterable<ClickEvent> elements, Collector<String> out) {
long windowStart = context.window().getStart();
long windowEnd = context.window().getEnd();
int count = 0;
for (ClickEvent event : elements) count++;
out.collect("窗口[" + windowStart + "-" + windowEnd + "], 用户" + s + "点击次数:" + count);
}
});
// 打印正常结果和迟到数据
result.print("正常计算结果");
result.getSideOutput(lateTag).print("迟到数据");
env.execute("EventTime & Watermark Demo");
}
// 自定义点击事件实体类
public static class ClickEvent {
private String userId;
private long eventTime;
// 构造器、getter/setter省略
}
}八、水印使用常见踩坑与优化技巧
坑点1:水印延迟设置不合理:延迟太短,丢数据;延迟太长,实时性变差。优化:根据业务数据延迟监控,设置平均延迟的1.5倍左右。
坑点2:多并行度水印卡住:空闲分区导致水印不推进。优化:添加withIdleness(Duration.ofSeconds(30)),标记30秒无数据的分区为空闲。
坑点3:事件时间提取错误:时间戳格式错误、单位错误(毫秒/秒混淆)。优化:统一用毫秒级时间戳,做好数据校验。
九、总结
最后梳理Flink时间与水印的核心要点,方便大家快速记忆:
生产环境优先用事件时间,配合水印处理乱序;
水印是时间进度标记,单调递增,核心是“最大事件时间-延迟时间”;
固定延迟水印是首选,简单高效;
多并行度水印取最小值对齐,空闲分区要设置超时;
迟到数据用允许延迟+侧输出流双层兜底,保证结果准确。
水印机制是Flink实现精准流处理的核心,理解了它的逻辑,就能轻松应对各类实时乱序数据场景,写出稳定、精准的Flink实时任务。
评论