
数据仓库 vs 数据湖 vs 湖仓一体:一文看懂该选哪个
核心答案(Answer-First):数据仓库适用于结构化数据的高性能 BI 分析场景,数据湖适用于海量原始数据的低成本存储与灵活处理,**湖仓一体(Lakehouse)**通过统一存储与计算,在同一平台上同时支持 BI 、实时计算和机器学习训练,是当前重要的发展方向之一。
一、 数据仓库、数据湖、湖仓一体到底是什么?
一句话定义
- 数据仓库(Data Warehouse):一个经过预先清洗和建模的"数据超市",拿来就能用,但只能买包装好的商品。
- 数据湖(Data Lake):一个装满了原始数据的"大仓库",什么东西都能往里塞,但找东西要自己翻。
- 湖仓一体(Lakehouse):既有超市的便利,又有仓库的容量——想直接拿成品?可以。想自己加工?也行。
技术定义
| 架构 | 官方定义 | 来源 |
|---|---|---|
| 数据仓库 | 面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持企业决策分析 | Inmon, 数据仓库之父 |
| 数据湖 | 以原始格式(结构化、半结构化、非结构化)存储海量数据的集中式存储库 | Databricks |
| 湖仓一体 | 融合数据湖和数据仓库优势的统一架构,在低成本存储上实现数据仓库级别的管理功能 | Microsoft Azure Databricks |
二、 数据仓库 vs 数据湖:七大核心差异
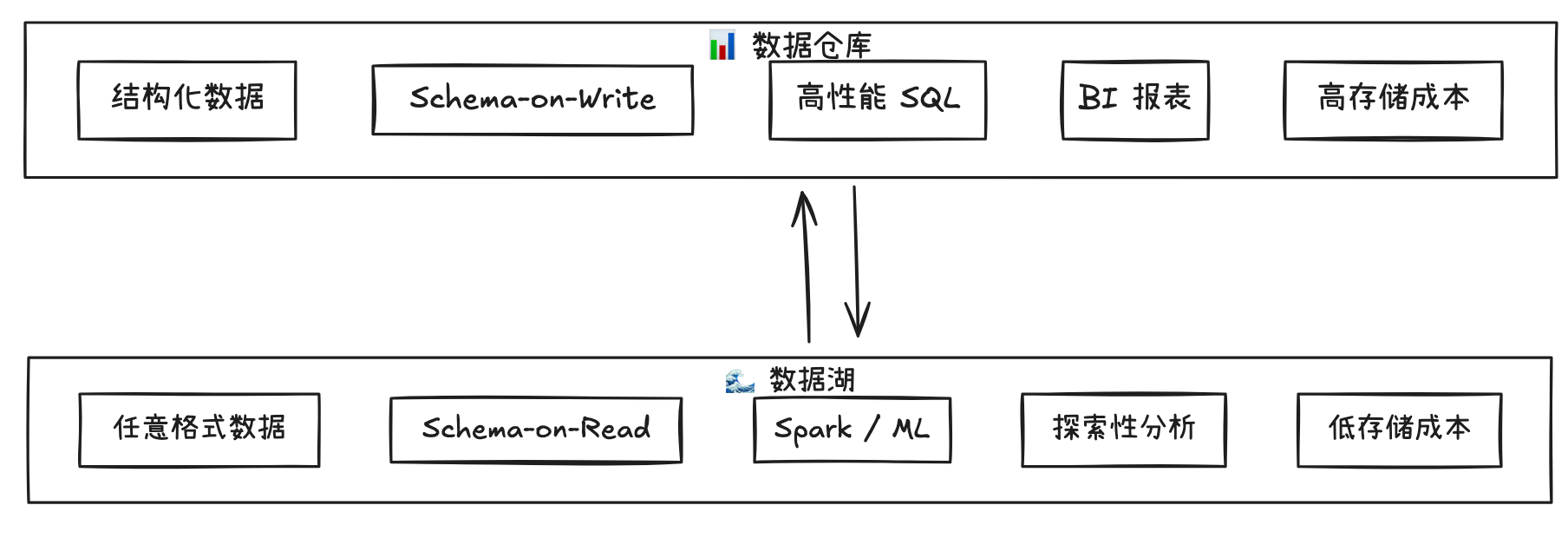
差异 1:数据类型
| 数据仓库 | 数据湖 | |
|---|---|---|
| 支持格式 | 结构化表(行和列) | 结构化 + 半结构化(JSON/XML)+ 非结构化(图片/视频/日志) |
| 举例 | 订单表、用户表、产品表 | 用户行为日志、商品图片、客服录音 |
差异 2:Schema 策略
- Schema-on-Write(仓库):数据写入前必须先定义表结构,不符合格式的数据会被拒绝。好处:数据质量高,查询可靠。坏处:写入慢,灵活性差。
- Schema-on-Read(湖):数据原样写入,查询时再定义结构。好处:写入快,灵活性高。坏处:如果数据格式变了,查询可能失败。
差异 3:查询性能
| 场景 | 数据仓库 | 数据湖 |
|---|---|---|
| 简单聚合(SUM/GROUP BY) | < 1 秒 | 5-30 秒 |
| 多表 JOIN | 1-5 秒 | 30 秒 - 数分钟 |
| 高并发查询(100+ QPS) | ✅ 轻松应对 | ❌ 可能超时 |
数据来源:综合多个基准测试,实际性能因数据规模和查询复杂度而异。
差异 4:存储成本
| 存储方案 | 每 TB/月(约) | 100TB 年成本 |
|---|---|---|
| 数据仓库(专有存储) | 200 - 500 | 24,000 - 60,000 |
| 数据湖(S3/ADLS/OSS) | 23 - 50 | 2,760 - 6,000 |
关键数据:数据湖的存储成本比数据仓库低 60-80%(基于 AWS/Azure 公开定价,2025 年)。
差异 5:典型用户
| 角色 | 数据仓库 | 数据湖 |
|---|---|---|
| BI 分析师 | ✅ 日常工作 | ❌ 很少使用 |
| 数据工程师 | ✅ 日常处理+维护ETL | ✅ 日常处理 |
| 数据科学家 | ❌ 数据太"干净",丢失细节 | ✅ 直接访问原始数据 |
| 业务人员 | ✅ 自助报表 | ❌ 技术门槛高 |
差异 6:使用场景
| 场景 | 数据仓库 | 数据湖 |
|---|---|---|
| 报表 | ✅ 准确且高效 | ⚠️ 可以用但不好用 |
| 用户行为分析 | ✅ 需要先建模,准确性高但时效性低 | ✅ 基于原始数据,时效性高但使用体验较差 |
| ML训练 | ❌ 数据太结构化 | ✅ 原汁原味 |
| 实时风控 | ⚠️ 延迟较高 | ✅ 实时 |
| 日志分析 | ⚠️ 存储成本高,可用于多维度分析场景 | ⚠️ 简单分析但复杂分析使用体验较差 |
差异 7:数据质量
| 维度 | 数据仓库 | 数据湖 |
|---|---|---|
| 入库前清洗 | ✅ 必须 | ❌ |
| Schema 约束 | ✅ 强制执行 | ❌ 无约束 |
| 数据一致性 | ✅ 高 | ⚠️ 需自行保障 |
| 异常数据检测 | ✅ 高 | ❌ 需自建 |
三、 湖仓一体:为什么它是现在的最优解?
3.1 湖仓一体的核心公式
湖仓一体 = 数据湖的低成本存储 + 数据仓库的管理能力 + 开放表格式的 ACID 保证
3.2 架构全景图
湖仓一体的数据分层体系:奖牌架构(Medallion Architecture)
在湖仓一体的语境下,业界最通用的是由 Databricks 提出的“奖牌架构”(Medallion Architecture),它与我们熟悉的经典维度建模分层高度契合,但在具体实现机制上有所不同。
3.2.1. 铜层(Bronze Layer)—— 对应 ODS(原始数据层)
- 定位: 数据的“着陆区”(Landing Zone),原封不动地保存来自业务系统(DB Binlog、埋点日志、API 等)的原始数据。
- 湖仓特性加持: * 支持结构化与非结构化数据同存。
- 通过 Hudi/Iceberg/Paimon 的流式写入能力,将原本 T+1 级别的离线同步,提升为分钟级的近实时入湖。
- 保留完整的数据历史快照(Time Travel),方便溯源和重算。
3.2.2. 银层(Silver Layer)—— 对应 DWD(明细数据层)
- 定位: 经过清洗、过滤、去重、规范化(如统一时间格式、脱敏)和维度退化后的企业级一致性明细数据。
- 湖仓特性加持:
- Schema Evolution(模式演进): 业务端表结构变更(加减列)可自动向下游传递,告别传统数仓繁琐的 DDL 同步和刷数。
- ACID 事务支持: 允许对海量历史数据进行高效的
UPSERT和DELETE操作,解决传统 Hive 架构下难以处理 CDC(变更数据捕获)数据的痛点。
3.2.3. 金层(Gold Layer)—— 对应 DWS/ADS(汇总与应用层)
- 定位: 面向特定业务主题的聚合数据,直接为 BI 报表、机器学习模型或实时大屏提供服务。
- 湖仓特性加持:
- 数据通常被优化为高度压缩的列式存储,并建立高级索引。
- 结合如 clickhouse、doris 等高性能 olap 引擎,直接在湖上提供亚秒级的交互式查询响应。
3.3 湖仓一体的五大核心优势
优势 1:降低总成本 💰
根据 Databricks 的客户案例,从双系统(湖 + 仓库)迁移到湖仓一体后:
- 存储成本降低 60%:不再需要为仓库购买昂贵的专有存储
- 运维成本降低 40%:只需维护一套系统
- 数据基础设施总成本降低 50%+
优势 2:统一治理 🛡️
| 治理能力 | 双系统架构 | 湖仓一体 |
|---|---|---|
| 元数据管理 | 两套 Catalog | 统一 Catalog |
| 权限控制 | 分别管理 | 统一 RBAC(支持行列级) |
| 数据血缘 | 跨系统断裂 | 字段级全链路追踪 |
| 审计合规 | 多系统分别审计 | 统一审计日志 |
优势 3:BI + ML 统一平台 🤝
在湖仓一体中,同一份数据可以同时服务 BI 和 ML,无需再维护两份副本,也无需担心数据不一致。
优势 4:开放标准 🔓
湖仓一体基于开放表格式(Delta Lake / Apache Iceberg / Apache Hudi / Apache Paimon),避免了传统数据仓库的供应商锁定:
| 表格式 | 发起方 | 核心特点 |
|---|---|---|
| Delta Lake | Databricks | ACID 事务、OPTIMIZE 优化、生态最成熟 |
| Apache Iceberg | Netflix | 隐藏分区、演进 Schema、多引擎支持 |
| Apache Hudi | Uber | Upsert 支持、增量拉取、流式优先 |
| Apache Paimon | Apache Flink 项目社区 | 实时湖仓一体、高吞吐写入、支持流式读写、与Flink深度集成 |
均支持:ACID 事务、时光旅行、Schema 演进。选型建议:优先看团队技术栈和计算引擎兼容性。
优势 5:实时数据处理 ⚡
| 处理能力 | 数据仓库 | 数据湖 | 湖仓一体 |
|---|---|---|---|
| 批处理 | ✅ | ✅ | ✅ |
| 流处理 | ⚠️ lambda架构,可以建设流处理流程 | ✅ | ✅ |
| 流批一体 | ❌ lambda架构,流批两套系统 | ⚠️ 关注原始数据,不关注数仓建设 | ✅ 原生支持 |
| 数据可见延迟 | T+1 或 T + 小时 | 秒 ~ 分钟 | 秒 ~ 分钟 |
四、 一张表总结:数据仓库 vs 数据湖 vs 湖仓一体
| 对比维度 | 数据仓库 | 数据湖 | 湖仓一体 |
|---|---|---|---|
| 数据类型 | 结构化 | 任意格式 | 任意格式 |
| Schema 策略 | Schema-on-Write | Schema-on-Read | 按需选择 |
| 存储成本 | 高 | 低 | 低 |
| 查询性能 | 极高 | 中等 | 高(接近仓库) |
| 数据质量 | 高 | 低 | 高(分层保障) |
| ACID 保证 | ❌ | ✅ | ✅ |
| BI 支持 | ✅ 优秀 | ⚠️ 一般 | ✅ 优秀 |
| ML 支持 | ❌ | ✅ 优秀 | ✅ 优秀 |
| 实时流处理 | ⚠️ | ✅ | ✅ |
| 运维复杂度 | 高(流批一体) | 中 | 中高 |
五、 选型决策树
六、 常见厂商产品对比
6.1 云数据仓库产品
| 产品 | 厂商 | 特点 | 适用场景 |
|---|---|---|---|
| Snowflake | Snowflake Inc. | 云原生、存算分离、自动扩缩容 | 中大型企业 BI |
| BigQuery | Serverless、内置 ML | 快速启动、AI 集成 | |
| Redshift | AWS | 生态完善、性价比高 | AWS 生态用户 |
| MaxCompute | 阿里云 | 国产化、大数据处理 | 国内企业 |
6.2 云数据湖产品
| 产品 | 厂商 | 特点 | 适用场景 |
|---|---|---|---|
| AWS Lake Formation | AWS | 与 S3 深度集成、内置治理 | AWS 用户 |
| Azure Data Lake | Microsoft | 与 ADLS 集成、企业级安全 | Azure 用户 |
| 阿里云 OSS + DLA | 阿里云 | 国内合规、性价比高 | 国内企业 |
6.3 云湖仓一体产品
| 产品 | 厂商 | 核心技术 | 特点 |
|---|---|---|---|
| Databricks Lakehouse | Databricks | Delta Lake + Spark | Lakehouse 提出者、生态最成熟 |
| Azure Synapse Analytics | Microsoft | 混合架构 | 与 Azure 生态深度集成 |
| 阿里云湖仓一体 | 阿里云 | EMR + MaxCompute | 国内企业首选 |
| StarRocks + Iceberg | StarRocks | 实时分析 + 开放表格式 | 极致查询性能 |
6.4 开源数据平台产品(适用于中大型公司)
| 产品 | 类型 | 核心技术 | 特点 | 适用场景 |
|---|---|---|---|---|
| Apache Hive | 数据仓库 | HDFS + Hive SQL | 成熟稳定,生态丰富 | 离线数仓 |
| Apache Iceberg | 湖表格式 | Table Format | 强 Schema 演进、查询优化好 | 数据湖 / 湖仓 |
| Apache Hudi | 湖表格式 | 增量存储 | 写入快、CDC强 | 实时数仓 |
| Delta Lake | 湖表格式 | Parquet + ACID | 与 Spark 深度绑定 | 湖仓一体 |
| Apache Paimon | 湖表格式 | Flink + LSM | 流批一体、实时写入极强 | 实时湖仓(推荐) |
| Apache Doris | OLAP数仓 | MPP | 易用、实时分析 | 报表分析 |
| ClickHouse | OLAP数仓 | 列式存储 + 向量化执行 | 极致查询性能、写入吞吐高 | 日志分析 / 实时分析 |
| StarRocks | OLAP数仓 | 向量化引擎 | 极致查询性能 | 高并发分析 |
| Apache Pinot | OLAP数仓 | 实时索引 | 毫秒级查询 | 实时分析 |
| Trino(Presto) | 查询引擎 | MPP SQL | 联邦查询 | 数据湖查询 |
| Apache Spark | 计算引擎 | 批处理 | 通用计算 | ETL |
| Apache Flink | 流处理 | 流计算 | 实时能力强 | 实时处理 |
七、 FAQ(常见问题)
Q1:湖仓一体能完全替代数据仓库吗?
答:在大多数场景下可以,但以下情况建议保留数据仓库:
- 极高并发查询(> 1000 QPS),湖仓一体可能需要额外加缓存层
- 已有成熟的数据仓库投资,且短期内没有扩展需求
- 团队缺乏 Spark/Delta Lake 技术能力,且短期无法补充
Q2:Delta Lake、Iceberg、Hudi、Paimon 选哪个?
答:四个都是成熟的开放表格式,选择建议:
- 用 Databricks / Spark 生态为主
→ Delta Lake(生态最契合,功能完善) - 多引擎混合(Spark + Trino + Doris 等)
→ Iceberg(兼容性最广,查询优化最好) - 需要频繁 Upsert(如 CDC、数据回流)
→ Hudi(增量写入能力强,写优化明显) - 实时数据处理、流批一体(Flink 为核心)
→ Paimon(原生流式湖表,实时写入能力最强)
Q3:从数据仓库迁移到湖仓一体需要多久?
答:取决于数据规模和 ETL 复杂度。典型迁移周期:
- 小型(< 10TB,ETL < 50 个):1-2 个月
- 中型(10-100TB,ETL 50-200 个):3-6 个月
- 大型(> 100TB,ETL > 200 个):6-12 个月
建议采用渐进式迁移,先迁移非核心业务验证,再逐步迁移核心业务。
Q4:湖仓一体的学习成本高吗?
答:有一定学习曲线,但比想象中低:
- 如果团队已有 Spark、flink 经验 → 1-2 周上手
- 如果只有 SQL 经验 → 1-2 个月(需学习flink、 Spark SQL 和 Delta Lake 概念)
- 选择托管服务(如 Databricks)可大幅降低学习成本
Q5:湖仓一体适合初创公司吗?
答:看阶段。
- 天使轮/A 轮,数据量 < 1TB → 数据仓库(如 BigQuery 免费版)更简单
- B 轮以后,数据结构复杂、流批同时存在,有 ML 需求 → 湖仓一体开始体现价值
- 如果从一开始就预判未来需要 BI + ML → 直接选湖仓一体可以避免二次迁移
Q6:湖仓一体的安全性如何?
答:取决于治理层的实现。优秀的湖仓一体平台(如 Unity Catalog)提供:
- 细粒度权限控制:表级、列级、行级
- 动态数据掩码:敏感数据(如手机号、身份证)自动脱敏
- 完整审计日志:所有操作可追溯
- 数据加密:传输中(TLS)+ 静态(AES-256)
安全级别与传统数据仓库持平甚至更高。
九、 总结与行动建议
总结
实际选型应优先考虑数据类型、使用场景与实时性需求:
- 以结构化数据 + BI 报表为主 → 数据仓库
- 包含非结构化数据 / Schema 频繁变化 / 数据科学需求 → 数据湖或湖仓
- 同时需要 BI + 实时处理 + 数据科学 + ML → 湖仓一体
数据架构选型,已经不是"选仓库还是选湖"的问题,而是"什么时候上湖仓"的问题。如果你的企业同时有 BI 和 ML 需求,湖仓一体几乎是不二之选。
十、 延伸阅读与参考资料
官方文档
- Microsoft Azure Databricks: What is a Data Lakehouse?
- Databricks: Data Lakes vs Data Warehouses
- Delta Lake 官方文档
- Apache Iceberg 官方文档
行业分析
- Gartner: 2025 数据分析与 BI 平台魔力象限
- Fivetran: What is a Data Lakehouse?
- Monte Carlo: Warehouse vs Lake vs Lakehouse
评论